
今天开始对实习过程中的工程进行简单的总结,不涉及业务。
这里使用的py去实现一个后端架构,但是这里使用的后台框架并非是类似于Django或者是flask等框架。而是单纯使用原生的方式去实现,用法其实和C++写后台没有本质的区别,仅仅是因为编程语言不同。
这里的后端,其实也大绝大多数的后端架构类似,都是采用B/S三层架构,有专门的Controller层去接受请求,也有专门的ORM层去DB访问数据。
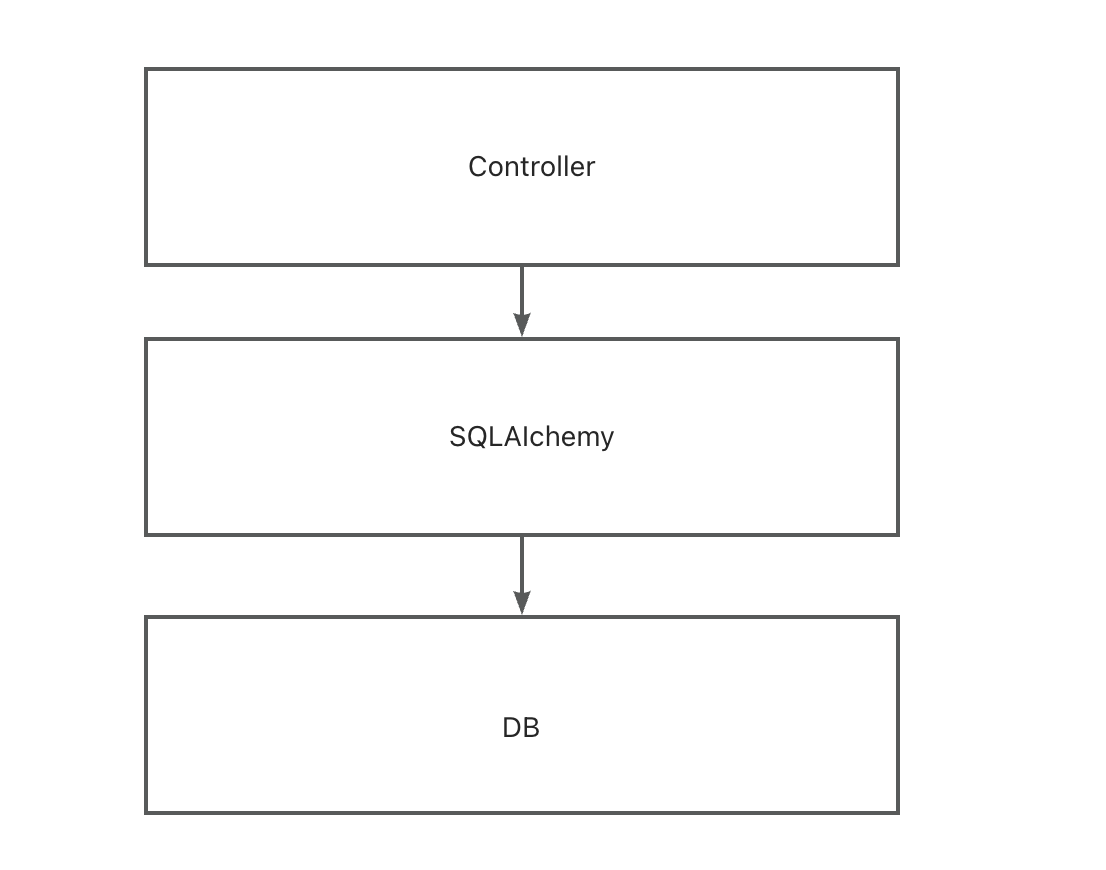
这样的系统还是比较类似的,但是也有着很大的不同。
rpc
比如说,这里的Controller层接受的不在是http请求,而是rpc请求。
1 |
|
这里的rpc协议请求使用的都是proto文件去定义的
1 | add.py -s=combo -f=ModifyBizTemplateSave --build |
通过命令去rebuild proto,s是模块,f是方法,这样会生成相应的proto映射文件
看到这里大家可能会感到疑惑,这个接口全都是rpc调用,难道前端会发起rpc请求吗?那当然不会,前端发起的显然都是http请求,不过中间有一层网关,会将所有的http请求都转为rpc请求,这一层的主要目的与单体服务无关,之所以要这么做最大的目的是为让所有的服务都能够互通。
这里可能和传统的Spring全家桶的微服务不一样,在以往的微服务架构之间,所有的前端发起,后端接收的请求都是http,而服务与服务之间发送的请求基本都是RPC,这可能是一种规范,为了提升效率的规范。但是我目前工作中使用的架构全都是基于Service Mesh的,也就是说,在所有的服务下面都有一层Mesh层,服务与服务之间不能够直接通信,就算是显示的发送RPC请求,服务的链路都是先传入底下的mesh层,再由mesh层传到目标服务的。
这种解决方案目的其实也是为了解开耦合,从而提供高内聚的能力,基本每个服务根本不用去在意自己的rpc,自己的基础设施,应该是什么样的版本,什么样的协议与组件。可以说,因为有了mesh层,可以极大的杜绝了重复造轮子导致的资源浪费。
orm
使用session = get_session(),可以根据需要去获取当前的session。目的是为了获取一个数据库会话对象。这里做了层层的封装,比如说当前的orm是否需要事务等等,都会进行一定程度的判定,最后才会返回一个最终的实例,我们就是通过操作这个实例,去进行保存和更新的。
这里的做法不像是Spring全家桶的风格,不过倒是和Go后端非常相似
通过session.query去获取表后,根据使用需求进行操作,比如
session.query(表名).filter(
表名.属性 == aaa.bbb, 表名.属性 == aaa.bbb
).first()
这样就可以获取到相应的数据了,这种写法非常简单,基本没有什么特别难的点
我们还可以进入MySQL,show create table, SHOW INDEX FROM 数据表;查看表信息,这些都是基本的操作了
debug
梳理一下逻辑,现在主要学习如何去排查问题,这里使用原生的调试器,去排查问题。
Pdb是Python自带的调试器,它可以帮助你在程序运行时暂停程序的执行,查看变量的值,执行代码行,以及跟踪程序的执行流程。使用Pdb可以帮助你快速定位代码中的错误,并且可以提高代码的可读性和可维护性。
使用Pdb非常简单,只需要在代码中插入一行
1 | import pdb; |
当程序执行到这一行时,程序会暂停执行并进入Pdb调试模式。在Pdb模式下,你可以使用一系列命令来查看变量的值,执行代码行,以及跟踪程序的执行流程。
例如:
可以使用p命令来查看变量的值
使用n命令来执行下一行代码
使用c命令来继续执行程序。
使用h命令是查看有哪些命令
可以使用args查看具体是什么问题
使用u和d分别对应上游和下游