关于Elasticsearch和spring-es—Data的实战汇总
基本概念
是什么
Elasticsearch是一个搜索的服务器,可以抽象为类似数据库的一样的东西。但是它本身的作用并不抽象,很大的业务作用都与数据库有着很大的重合。原理是倒排索引,这篇文章就不细说了
举例子
一
比如说,在我们需要使用数据库进行搜索的时候,直接模糊查询就好了 select id from item where itemName like %xxx% 但是这样的查询并不完美,比如我要找电子产品,我输入手机,那么和产品名称为手机的都会严格的被查询回来,可是这样就无法找到类似于:智能机,老人机,这样的称呼,这样很明显是不可学的,那我们是将手机再拆分为两个SQL进行查找吗?也许这样可行,但是对于手这个单词的查找可能会找到手套之类的物品,而这样已经违背的我们的初衷,明显,仅仅在数据库使用like是不明智的选择
二
性能问题。我们在进行数据库查找的时候,更多的是这样:
这种like或者where的一行一行的查找,在对于海量的数据的时候,性能会变得非常的差劲,以致于能影响我们数据库的正常使用,使用了Elasticsearch之后,数据会在ES中有备份,而这样的查找就变成了:
这正是Elasticsearch的特性。
数据类型
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
1 | 索引(indices)---------------------------------Databases 数据库 |
详细说明:
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引, |
| 类型(type) | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 映射配置(mappings) | 字段的数据类型、属性、是否索引、是否存储等特性 |
另外,在SolrCloud中,有一些集群相关的概念,在Elasticsearch也有类似的:
- 索引集(Indices,index的复数):逻辑上的完整索引 collection1
- 分片(shard):数据拆分后的各个部分
- 副本(replica):每个分片的复制
要注意的是:Elasticsearch本身就是分布式的,因此即便你只有一个节点,Elasticsearch默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
基本语法
安装好了可以直接使用你的localhost地址,加上端口访问,
1 | http://192.168.78.128:9200/ |
首页会出现:
1 | { |
而这些都是它的基本情况
http请求
get
Elasticsearch采用Rest风格API,因此其API就是一次http请求
1 | GET /索引库名 |
这样会展现出我们这个索引库的所有数据
delete
1 | DELETE /索引库名 |
删除索引库
put
而当我们需要往Elasticsearch放入数据时,建议使用Elasticsearch—DATA 使用我们的外部API来放入我们的数据。
当然也有原生的API:
1 | PUT /索引库名/_mapping/类型名称 |
- 类型名称:就是前面将的type的概念,类似于数据库中的不同表
字段名:任意填写 ,可以指定许多属性,例如: - type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:分词器,这里的
ik_max_word即使用ik分词器
1 | GET /索引库名/_mapping |
而使用这个方法可以查看我们的各个字段的类型
官方文档中有对类型的具体阐述:
String类型,又分两种:
- text:可分词,不可参与聚合
- keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
Numerical:数值类型,分两类
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间
index
index影响字段的索引情况。
- true:字段会被索引,则可以用来进行搜索。默认值就是true
- false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。
在我们实体对Class进行操作的时候,可以进行手动标注
Post
通过POST请求,可以向一个已经存在的索引库中添加数据:
1 | POST /索引库名/类型名 |
并可以通过:
1 | get /索引库名/_search |
去查看我们的所有数据。
这些都是原生的操作方法,但是实际操作过程中,并不会使用这种方法去操作,在Spring中也提供了相应的data-es去操作
查询
基本查询
查询所有
1 | GET /索引库名/_search |
这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:例如:
match_all,match,term,range等等
1 | GET /索引库名/_search |
查询所有
则会在返回的JSON头出现
1 | { |
- took:查询花费时间,单位是毫秒
- time_out:是否超时
- _shards:分片信息
- hits:搜索结果总览对象
- total:搜索到的总条数
- max_score:所有结果中文档得分的最高分
- hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
- _index:索引库
- _type:文档类型
- _id:文档id
- _score:文档得分
- _source:文档的源数据
匹配查询
or
使用:
1 | http://192.168.78.128:9200/product/_search |
1 | { |
可以得出:

match类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系
and
某些情况下,我们需要更精确查找,我们希望这个关系变成and,可以这样做:
1 | { |
or和and
在 or 与 and 间二选一有点过于非黑即白。 如果用户给定的条件分词后有 5 个查询词项,想查找只包含其中 4 个词的文档,该如何处理?将 operator 操作符参数设置成 and 只会将此文档排除。
有时候这正是我们期望的,但在全文搜索的大多数应用场景下,我们既想包含那些可能相关的文档,同时又排除那些不太相关的。换句话说,我们想要处于中间某种结果。
match 查询支持 minimum_should_match 最小匹配参数, 这让我们可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量:
1 | { |
本例中,搜索语句可以分为3个词,如果使用and关系,需要同时满足3个词才会被搜索到。这里我们采用最小品牌数:75%,那么也就是说只要匹配到总词条数量的75%即可,这里3*75% 约等于2。所以只要包含2个词条就算满足条件了。
如图: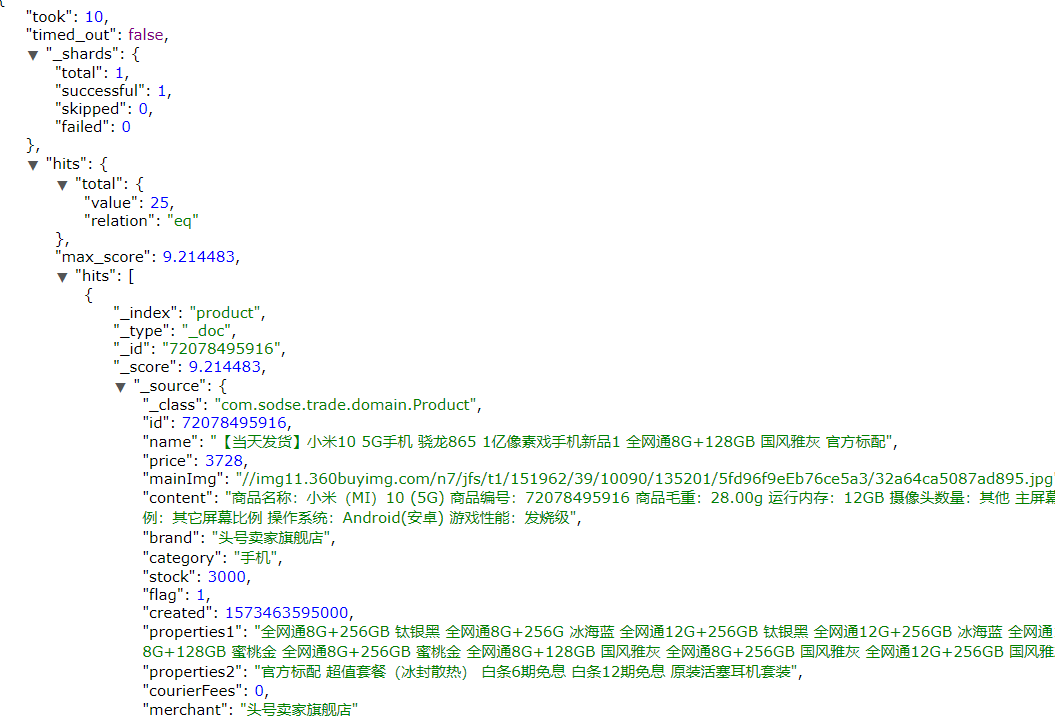
多字段查询
1 | { |
词条匹配
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串
1 | { |
多词条精确匹配
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件:
1 | { |
1 | { |
结果过滤
直接指定字段
默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source的过滤:
1 | { |
1 | { |
指定includes和excludes
我们也可以通过:
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
1 | { |
结果如图: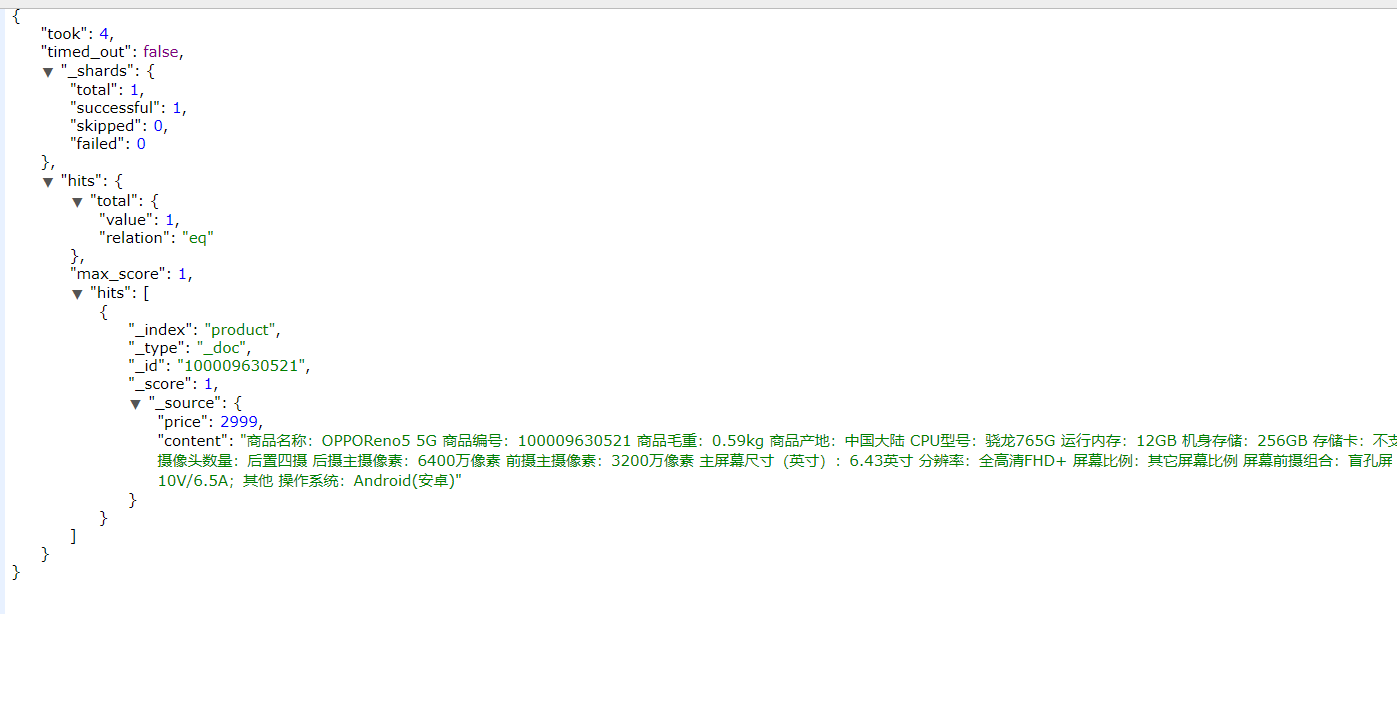
高级查询
布尔组合
bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合
1 | { |
如图: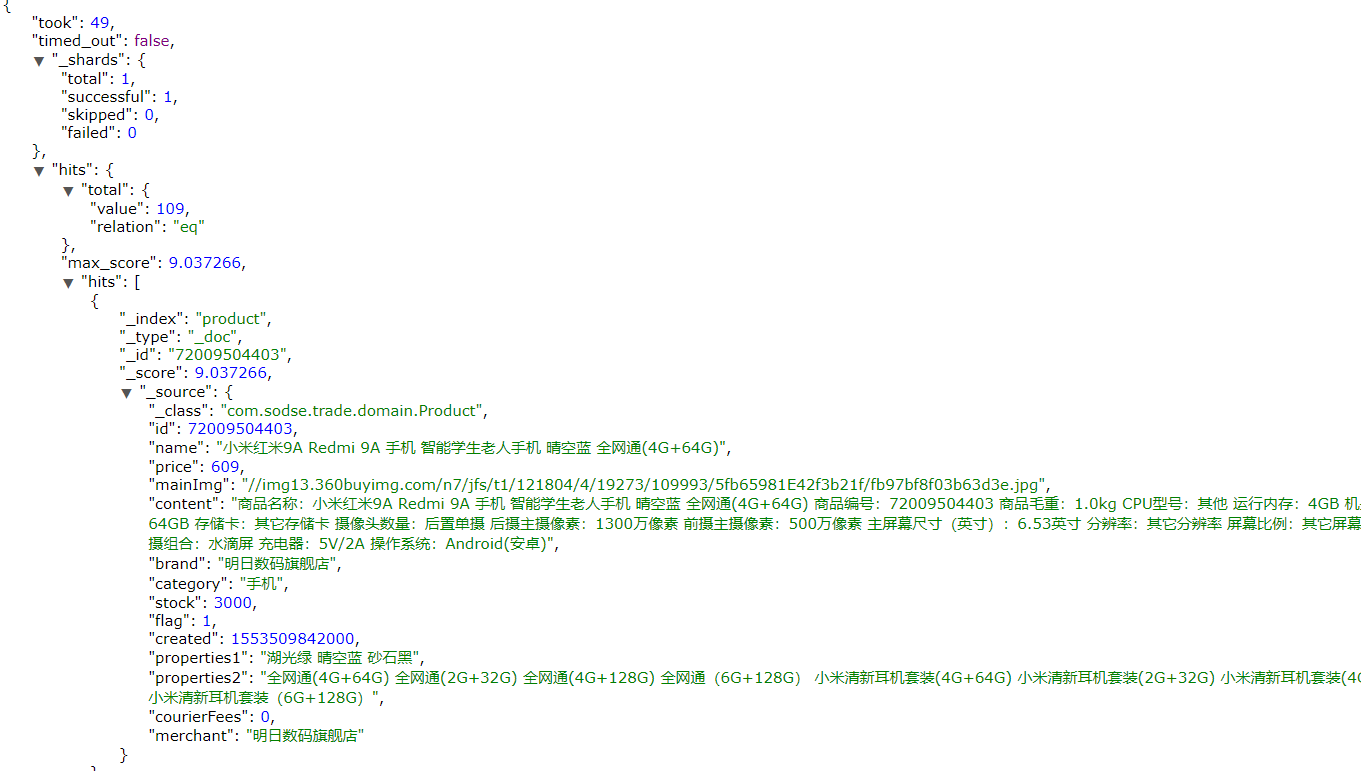
范围查询
1 | { |
range查询允许以下字符:
| 操作符 | 说明 |
|---|---|
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
模糊查询
fuzzy查询是 term 查询的模糊等价。它允许用户搜索词条与实际词条的拼写出现偏差,但是偏差的编辑距离不得超过2:
1 | { |
我们可以通过fuzziness来指定允许的编辑距离:
1 | { |
过滤
条件查询中进行过滤
所有的查询都会影响到文档的评分及排名。如果我们需要在查询结果中进行过滤,并且不希望过滤条件影响评分,那么就不要把过滤条件作为查询条件来用。而是使用filter方式:
1 | { |
无查询条件,直接过滤
如果一次查询只有过滤,没有查询条件,不希望进行评分,我们可以使用constant_score取代只有 filter 语句的 bool 查询。在性能上是完全相同的,但对于提高查询简洁性和清晰度有很大帮助。
1 | { |
排序
单字段排序
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式
1 | { |
多字段排序
假定我们想要结合使用 price和 _score(得分) 进行查询,并且匹配的结果首先按照价格排序,然后按照相关性得分排序:
1 | { |
聚合aggregations
聚合可以让我们极其方便的实现对数据的统计、分析。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现实时搜索效果。
基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量:
桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个桶,例如我们根据国籍对人划分,可以得到中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:010,1020,2030,3040等。
Elasticsearch中提供的划分桶的方式有很多:
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
- Histogram Aggregation:根据数值阶梯分组,与日期类似
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
- ……
bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为度量
比较常用的一些度量聚合方式:
- Avg Aggregation:求平均值
- Max Aggregation:求最大值
- Min Aggregation:求最小值
- Percentiles Aggregation:求百分比
- Stats Aggregation:同时返回avg、max、min、sum、count等
- Sum Aggregation:求和
- Top hits Aggregation:求前几
- Value Count Aggregation:求总数
- ……
聚合为桶
这里我使用了产品的category来分类,聚合为不同的桶:
1 | {"size":0,"aggs":{"popular_category":{"terms":{"field":"category"}}}} |
- size: 查询条数,这里设置为0,因为我们不关心搜索到的数据,只关心聚合结果,提高效率
- aggs:声明这是一个聚合查询,是aggregations的缩写
- popular_category:给这次聚合起一个名字,任意。
- terms:划分桶的方式,这里是根据词条划分
- field:划分桶的字段
- terms:划分桶的方式,这里是根据词条划分
- popular_category:给这次聚合起一个名字,任意。
但是,这里我出现了一个错误:
1 | fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [interests] in order to load field data by uninverting the inverted index. Note that this can use significant memory. |
大意就是必须把我们的属性设置为:set fielddata=true。
这里时候我返回idea,使用注解:
1 | (type = FieldType.Text,fielddata = true) |
将字段变为fielddata = true,可是这样一样出现这样的错误,这是为什么呢?
紧急错误
之后我通过
1 | http://192.168.78.128:9200/_mapping |

发现了这个错误的原因,原来是这个@field注解并没有生效,所以属性也没有生效。
之后在网上搜索各个文章,发现很多的做法都是使用外置一个json,也有一部分是用createindex+putindex。
使用json明显不是官方的做法,简直越来越复杂,而createindex和putindex一起使用也不正确,后来看了看官方文档,标注这两个方法都被弃用了,而且createindex其实已经集成到repository里面自动产生了,很迷惑。
但是在多次调试的情况下,我获得了两种答案:
解决方案一
先使用:
1 | elasticsearchRestTemplate.putMapping(Product.class); |
将mapping配置放入es连接中,再使用saveALL就行了
二是升级版本,把springboot升级到2.4.0
之后便是再次尝试: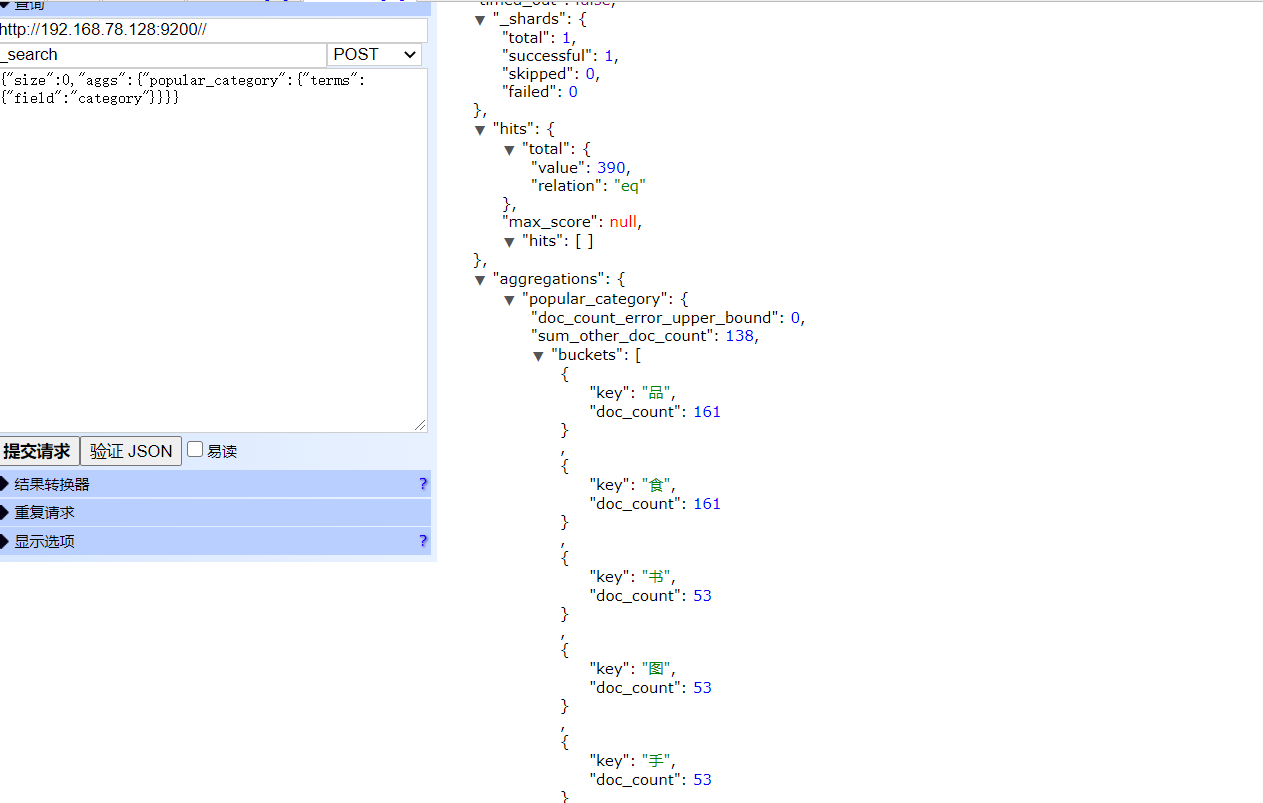
- hits:查询结果为空,因为我们设置了size为0
- aggregations:聚合的结果
- popular_category:我们定义的聚合名称
- buckets:查找到的桶,每个不同的category字段值都会形成一个桶
- key:这个桶对应的category字段的值
- doc_count:这个桶中的文档数量
桶内度量
我们需要告诉Elasticsearch使用哪个字段,使用何种度量方式进行运算,这些信息要嵌套在桶内,度量的运算会基于桶内的文档进行
现在,我们为刚刚的聚合结果添加 求价格平均值的度量:
1 | { |
- aggs:我们在上一个aggs(popular_colors)中添加新的aggs。可见
度量也是一个聚合 - avg_price:聚合的名称
- avg:度量的类型,这里是求平均值
- field:度量运算的字段
结果如图:
桶内嵌套桶
刚刚的案例中,我们在桶内嵌套度量运算。事实上桶不仅可以嵌套运算, 还可以再嵌套其它桶。也就是说在每个分组中,再分更多组
1 | { |
- 原来的color桶和avg计算我们不变
- maker:在嵌套的aggs下新添一个桶,叫做maker
- terms:桶的划分类型依然是词条
- filed:这里根据make字段进行划分
划分桶的其它方式
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
- Histogram Aggregation:根据数值阶梯分组,与日期类似
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
Histogram
histogram是把数值类型的字段,按照一定的阶梯大小进行分组。你需要指定一个阶梯值(interval)来划分阶梯大小。
举例:
比如你有价格字段,如果你设定interval的值为200,那么阶梯就会是这样的:
0,200,400,600,…
上面列出的是每个阶梯的key,也是区间的启点。
如果一件商品的价格是450,会落入哪个阶梯区间呢?计算公式如下:
1 | bucket_key = Math.floor((value - offset) / interval) * interval + offset |
value:就是当前数据的值,本例中是450
offset:起始偏移量,默认为0
interval:阶梯间隔,比如200
因此你得到的key = Math.floor((450 - 0) / 200) * 200 + 0 = 400
1 | { |
结果如图所示:
同样还可以指定: “min_doc_count”: 1 去表达,只有存在最小区间的才展示。
spring-boot-starter-data-elasticsearch
这里使用的SpringBoot版本是2.3.7。spring-boot-starter-data-elasticsearch版本为2.4.2、
elasticsearch版本为7.6.2
首先导入pom文件,然后,新版本的elasticsearch建议使用Configuration器配置:
1 |
|
然后是实体类:
1 | (indexName = "product", shards = 1, replicas = 0) |
@ApiModelProperty和ApiModel是我自己的swagger依赖,和Elasticsearch无关。
Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
- @Document作用在类,标记实体类为文档对象,一般有四个属性
- indexName:对应索引库名称
- type:对应在索引库中的类型
- shards:分片数量,默认5
- replicas:副本数量,默认1
- @Id` 作用在成员变量,标记一个字段作为id主键
- @Field作用在成员变量,标记为文档的字段,并指定字段映射属性:
- type:字段类型,取值是枚举:FieldType
- index:是否索引,布尔类型,默认是true
- store:是否存储,布尔类型,默认是false
- analyzer:分词器名称:ik_max_word
值得注意的是:@Document的type在新版本被弃用了。
基本操作
这里通过继承ElasticsearchRepository来像JPA一样使用它的API
1 | public interface ProductRepository extends ElasticsearchRepository<Product ,Long> { |
接下来看看常规的操作
增加
1 |
|
productRepository.index() 是 过去弃用的方法,现今使用productRepository.save 去保存一个Object。
更新和保存同样都是使用save,它会根据主键是否相同来判断是更新还是保存新数据
1 |
|
productRepository.saveAll 保存一个List 数据
删除
1 |
|
查询
1 |
|
可以通过像JPA一样自定义方法来进行增删改查操作
1 | productRepository.findAll(Sort.by(Sort.Direction.DESC, "price")); |
还可以选择降序排序等等
自定义方法
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
当然,方法名称要符合一定的约定:
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And |
findByNameAndPrice |
{"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or |
findByNameOrPrice |
{"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is |
findByName |
{"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not |
findByNameNot |
{"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between |
findByPriceBetween |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual |
findByPriceLessThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual |
findByPriceGreaterThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before |
findByPriceBefore |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After |
findByPriceAfter |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like |
findByNameLike |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith |
findByNameStartingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith |
findByNameEndingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing |
findByNameContaining |
{"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In |
findByNameIn(Collectionnames) |
{"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn |
findByNameNotIn(Collectionnames) |
{"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near |
findByStoreNear |
Not Supported Yet ! |
True |
findByAvailableTrue |
{"bool" : {"must" : {"field" : {"available" : true}}}} |
False |
findByAvailableFalse |
{"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy |
findByAvailableTrueOrderByNameDesc |
{"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
高级操作
QueryBuilders
1 |
|
QueryBuilders提供了大量的静态方法,用于生成各种不同类型的查询对象,例如:词条、模糊、通配符等QueryBuilder对象。如图:
NativeSearchQueryBuilder
1 |
|
NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体
Page:默认是分页查询,因此返回的是一个分页的结果对象,包含属性:
- totalElements:总条数
- totalPages:总页数
- Iterator:迭代器,本身实现了Iterator接口,因此可直接迭代得到当前页的数据
如图:
分页查询
1 |
|
结果如图:
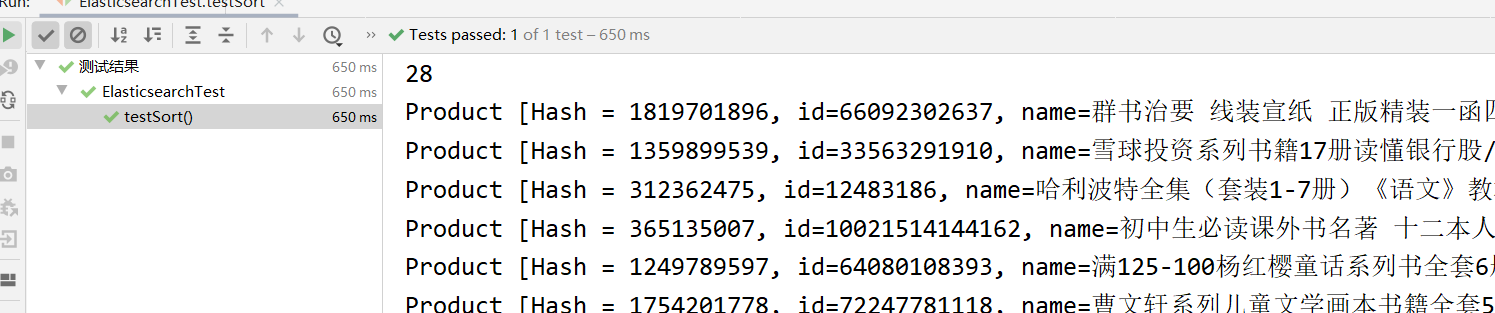
排序
1 |
|
结果如图: