使用ElasticSearch做全文检索
前言
关于ElasticSearch网络上有很多的教程。但是这些教程,讲的都不是很好,大多数都仅讲了,它是一个搜索服务器,一个搜索引擎,这种比较抽象的话,并没有解释他的是一个什么样的结构,这让我在当初学习的时候,有中无从下手的感觉。但如今对他有了一定的了解,于是乎,我打算把这些功能比较形象的写出来。
概念
这个概念比较关键,如果你能理解它的概念,那么你也能理解他的大部分逻辑了。
由来
首先你要明白搜索引擎这个概念。我们平常用的搜索引擎如,百度,谷歌等等。他们是怎么样在这上亿的数据量中快速的搜索到我们需要的内容呢?如果仅仅依靠数据库。,那么,会给数据库造成很大的压力,而且曾经上万的人可能在同一时间使用搜索引擎去搜索内容。数据库怎么可能承担了如此之多的数据量的访问呢?
那么我们根据之前所学的概念。我们可以尝试用的缓存去解决这个问题。对!把需要读取的需要读取的东西放入缓存中。如果需要再从缓存当中去读取。那么就不会给数据库造成很大压力了。但之前的缓存像Redis,它是一种类似于key- value的类型。那么对于千奇百怪的搜索内容,不同编码的字符串,redis是怎么能够能中搜索到呢?就算他能够实现。但是缓存这种东西。一般来说是不会把它设置为永久存在的。缓存一般有他的存活时间,他也没有像数据库那么稳定。所以单单是使用缓存去解决这个问题,明显不是最优的选择。
另外一个比较重要的一点就是,在一个商城中。我们一般都会实现搜索这种功能。但搜索功能是直接去访问数据库的。如果很多人进行搜索,那么海量的请求会给我们数据库造成极大的压力。所以我们也需要把这种东西拆分成两部分。用别的东西去代替搜索,或者说不直接从数据库访问数据。但是仅仅是Redis缓存明显不能够承担这种任务。
于是乎便诞生了ElasticSearch,这种NoSQL类型特殊的数据库型缓存。对,就是数据库类型的缓存。
工作流程
他的工作流程主要是:当用户需要某一个数据时,先从数据库里读取,再把这个数据加入到这个特殊的缓存当中。然后当我们需要某些内容的,他们就能够去这个特殊的缓存中读取数据。这种读取速度的方法跟一般的缓存不同的是,会根据内容关键词去进行搜索,只会的搜索出所需要的内容。
之后如若遇到有相同的关键词,就会去这个搜索服务器中搜索。将它的值或数据类型,返回给用户。而当我们这关键词在这搜索服务器中所显示数据量太少,或者说没有这个数据时,才会去数据库中再次读取数据。再补充到到搜索服务器当中。这个工作流程和Redis缓存非常的类似。但主要的区别在于,它是一个能够搜索和存储的数据库型缓存。
和Redis的主要区别
那这是不是代表了这个搜索服务器完全可以取代Redis这个缓存呢?其实这是不一样的。因为我们的这个搜索服务器,他虽然能对关键是进行搜索,但这搜索的效率相对缓存那样的key-value直接取值而言,并不是特别高,虽然说比数据库要快,但是单单论缓存的速度而言,是远远的比不上Redis的。
所以,当我们需要搜索的时候才会用这个搜索服务器。我们一般仅仅是使用缓存的话还是Redis比较快速。
应用场景
就一个商城项目而言,当我们需要去搜索的时候,就用这个搜索服务器,快速的将关键词拆分进搜索,然后返回出相应的内容,但是这些内容并不包含所有的信息。他只包含了一些比较关键的信息,就例如它的头标题或者是特定的图片等等。
然后等用户点进的这个链接。我们才会去从数据库中另外读取数据,或者说去Redis中读取数据。
实验
接下来我们就来进行一个实验,来尝试的使用这个搜索服务器。
但是这个东西操作有点困难,所以你必须先掌握docker的使用
譬如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| #要求熟练掌握
ip addr
service network restart
service docker start
docker pull xxx
docker images
docker ps
docker ps -a
docker run xxx
docker kill xxx
docker rm xxx
docker rename xxx yyy
docker image rm xxx
docker restart xxx
#了解
apt-get update
apt-get install vim
vim xxx
|
安装
1
2
3
4
5
| docker pull elasticsearch:xxx
#必须带版本号
#
docker run -d -e ES_JAVA_POTS="-Xms256m -Xmx256m" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 --name es01 f29a1ee41030
|
注意
如果你的云服务器内存不足1G的话,则使用:
1
2
3
4
5
6
| find / -name jvm.options
#
#
vim /var/lib/docker/overlay2/973a5c6a4450ab59e64d6ba7e78ed6622512c142e0a2f8164653b11e8b66baa9/diff/usr/share/elasticsearch/config/jvm.options
#进入,将-xms和-xmx参数,改为256m
|
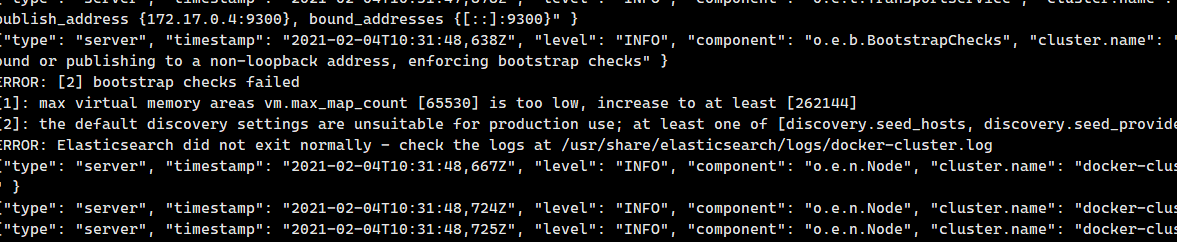
否则可能会出现:
配置文件
依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
| <dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
</dependency>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
|
这个依赖还包括其他东西。我们一般是用这个jest方法去使用elasticsearch。
yml
1
2
3
4
5
6
| spring:
elasticsearch:
jest:
uris:
- http://192.168.78.128:9200
read-timeout: 5000
|
实体类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| public class Entity implements Serializable {
private static final long serialVersionUID = -763638353551774166L;
public static final String INDEX_NAME = "index_entity";
public static final String TYPE = "tstype";
private Long id;
private String name;
public Entity() {
super();
}
public Entity(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
|
服务层
接口
1
2
3
4
5
6
7
8
| public interface TestService {
void saveEntity(Entity entity);
void saveEntity(List<Entity> entityList);
List<Entity> searchEntity(String searchContent);
}
|
实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| @Service
public class TestServiceImpl implements TestService {
private static final Logger LOGGER = LoggerFactory.getLogger(TestServiceImpl.class);
@Autowired
private JestClient jestClient;
@Override
public void saveEntity(Entity entity) {
Index index = new Index.Builder(entity).index(Entity.INDEX_NAME).type(Entity.TYPE).build();
try {
jestClient.execute(index);
LOGGER.info("ES 插入完成");
} catch (IOException e) {
e.printStackTrace();
LOGGER.error(e.getMessage());
}
}
@Override
public void saveEntity(List<Entity> entityList) {
Bulk.Builder bulk = new Bulk.Builder();
for(Entity entity : entityList) {
Index index = new Index.Builder(entity).index(Entity.INDEX_NAME).type(Entity.TYPE).build();
bulk.addAction(index);
}
try {
jestClient.execute(bulk.build());
LOGGER.info("ES 插入完成");
} catch (IOException e) {
e.printStackTrace();
LOGGER.error(e.getMessage());
}
}
@Override
public List<Entity> searchEntity(String searchContent){
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("name",searchContent));
Search search = new Search.Builder(searchSourceBuilder.toString())
.addIndex(Entity.INDEX_NAME).addType(Entity.TYPE).build();
try {
JestResult result = jestClient.execute(search);
System.out.println(result.toString());
return result.getSourceAsObjectList(Entity.class);
} catch (IOException e) {
LOGGER.error(e.getMessage());
e.printStackTrace();
}
return null;
}
}
|
接下来来到了重点,详细说一说。
先说saveEntity方法,这里要注意的就是:
1
| Index index = new Index.Builder(entity).index(Entity.INDEX_NAME).type(Entity.TYPE).build();
|
他到底做了什么呢?我们可以从index和type这两个,看到它是在为一个entity类实例建立一个索引名和索引类型,将两者绑定在一起,作为一个索引类型被执行。调用的是:
1
2
3
4
| public Builder(Object source) {
this.source = source;
this.id(AbstractAction.getIdFromSource(source));
}
|
可以看到,它没有对Entity做改动,而仅仅是加上一部分属于他的内容。
我们还可以从中获取到,这个index 类型还附带一个url:uri=index_entity/tstype,method=POST
将这个索引类型发送到我们的ES服务器当中。
接着,我们来看到下面的Search方法:
1
2
3
| SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("name",searchContent));
|
这个方法一开始就建立了一个对象,我们可以看到:QueryBuilders.matchQuery(“name”,searchContent)是对要搜索的内容,进行了一定程度的转换,那么转换成什么样子了呢?
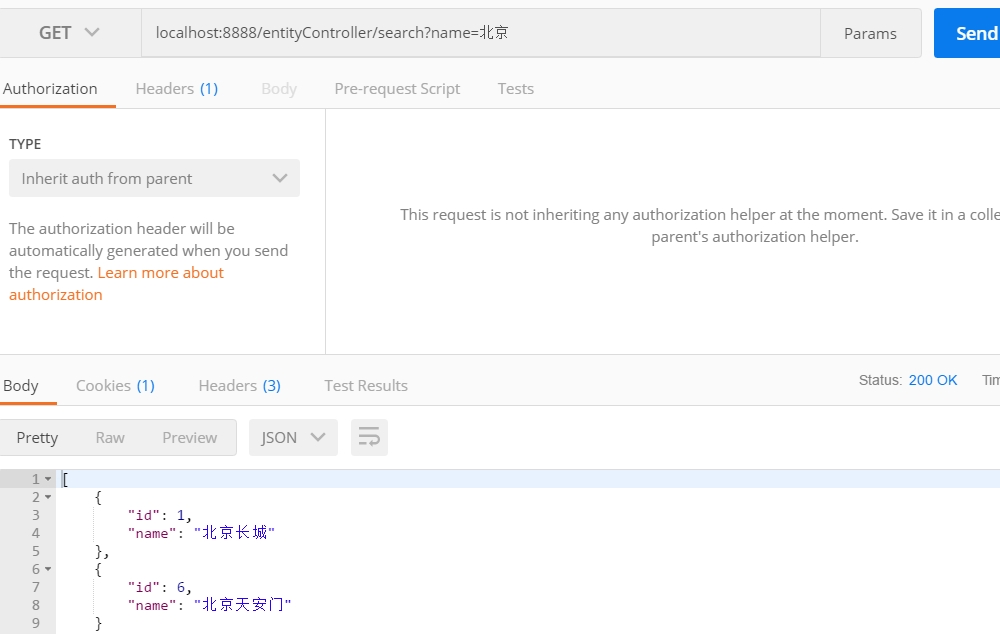
我们使用一个例子:entityController/search?name=北京 为例。进行搜索,我们来看看这个searchSourceBuilder:
1
2
3
4
5
6
7
8
9
10
| {
"query" : {
"match" : {
"name" : {
"query" : "北京",
"type" : "boolean"
}
}
}
}
|
变为了一个Json型对象,记住,他将要搜索的内容:北京,变为了一个Json对象。然后通过:
1
2
| Search search = new Search.Builder(searchSourceBuilder.toString())
.addIndex(Entity.INDEX_NAME).addType(Entity.TYPE).build();
|
封装成一个Url,发送到ES服务器。它里面的内容是:
1
| uri=index_entity/tstype/_search,method=POST
|
和添加类似,返回进了服务器当中。
控制层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| @RestController
@RequestMapping("/entityController")
public class EntityController {
@Autowired
TestService cityESService;
@RequestMapping(value="/save", method=RequestMethod.GET)
public String save(long id, String name) {
System.out.println("save 接口");
if(id>0 && StringUtils.isNotEmpty(name)) {
Entity newEntity = new Entity(id,name);
List<Entity> addList = new ArrayList<Entity>();
addList.add(newEntity);
cityESService.saveEntity(addList);
return "OK";
}else {
return "Bad input value";
}
}
@RequestMapping(value="/search", method=RequestMethod.GET)
public List<Entity> save(String name) {
List<Entity> entityList = null;
if(StringUtils.isNotEmpty(name)) {
entityList = cityESService.searchEntity(name);
}
return entityList;
}
}
|
控制层比较随意,接收参数,调用接口便可。
测试
我们可以安装ES-Head可视化插件,帮助我们查看里面的内容。
我们打开PostMan,输入 localhost:8888/entityController/save?id=1&name=北京长城,为其添加内容。
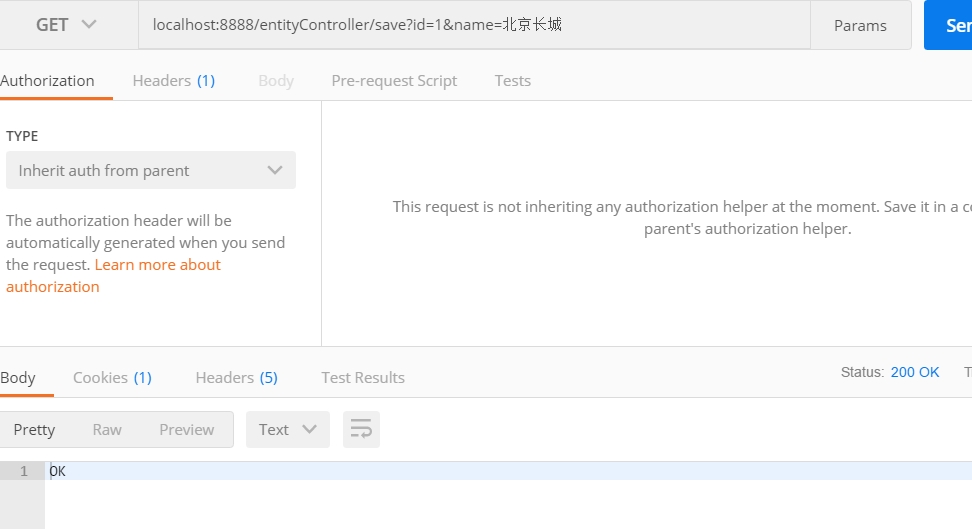
想这样子,添加很多内容
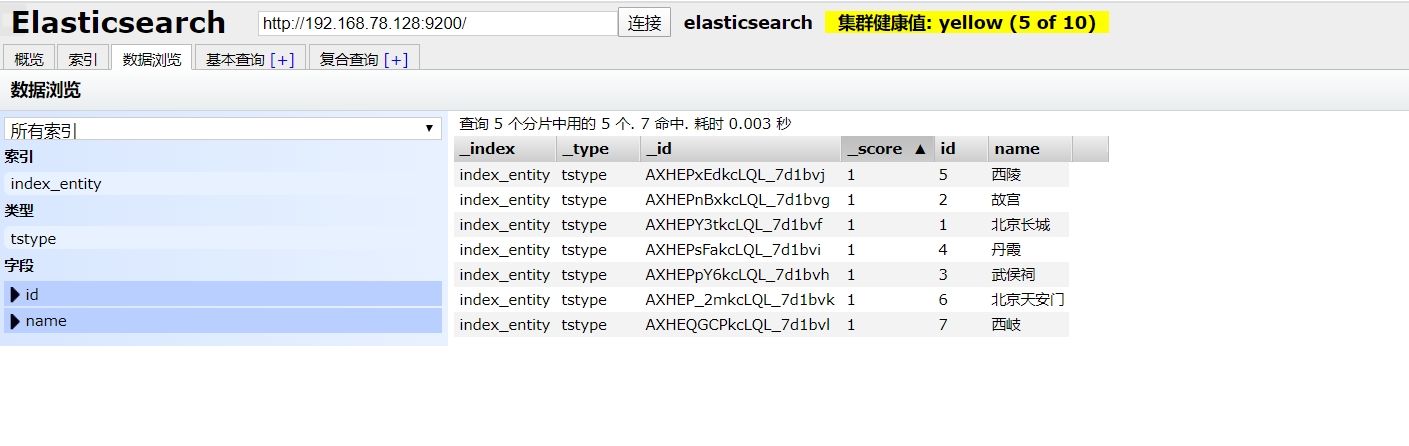
之后,可以使用方法进行搜索操作,搜到到的值,会以JSON形式,返回给我们,方便我们绑定对象实例。