利用Jsoup爬取网站数据
最近在做项目的时候,老师说项目的数据量太少了,并且说可以利用爬虫去爬取一些数据来填充自己项目的数据库。于是乎,我又动了一些歪心思。:call_me_hand:
虽然自己也自学过Python,但是手上的笔记本没有安装pycharm,为了实现一项功能而去特意安装一个软件,实在是有一点本末倒置。于是乎,就使用了Java的一个名为Jsoup的包,去实现网络爬虫,爬取数据。
Jsoup
虽然这东西有官方文档,但是说真的,看的有点乱,脑阔痛,于是就没看文档,直接看别人写的爬虫寻找逻辑。
看了一下别人写的爬虫,感觉挺长却又很没有营养。所以在理解了getElementsByClass和select的用法后,便决定自己一步一步写。所以,我写了一个很短却又效果很棒的爬虫。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public void douban(String url){
Document doc = null;
try {
doc = Jsoup.connect(url).userAgent("Mozilla").get();
} catch (IOException e) {
e.printStackTrace();
}
Elements div = doc.getElementsByClass("indent");
Elements table = div.select("table");
for (Element tb : table) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
Elements tr = tb.select("tr");
Elements img=tr.select("img");
String imgUrl = img.get(0).attr("abs:src");
System.out.println(imgUrl);
}
}
|
这个爬虫能够直接返回豆瓣网页图片的URL路径,可以非常快的把这些图片作为自己的数据源。
这里就简单的解释一下他们的用法,首先使用的是getElementsByClass,选中需要进行爬取的class标签,这个class标签的选取,最好越精确越好,即不要直接选取整个页面都使用的class,也不要选取很多细碎的文字样式的class,最佳的选取是选择一个盒模型中模块的class。作为我们的第一次筛选。
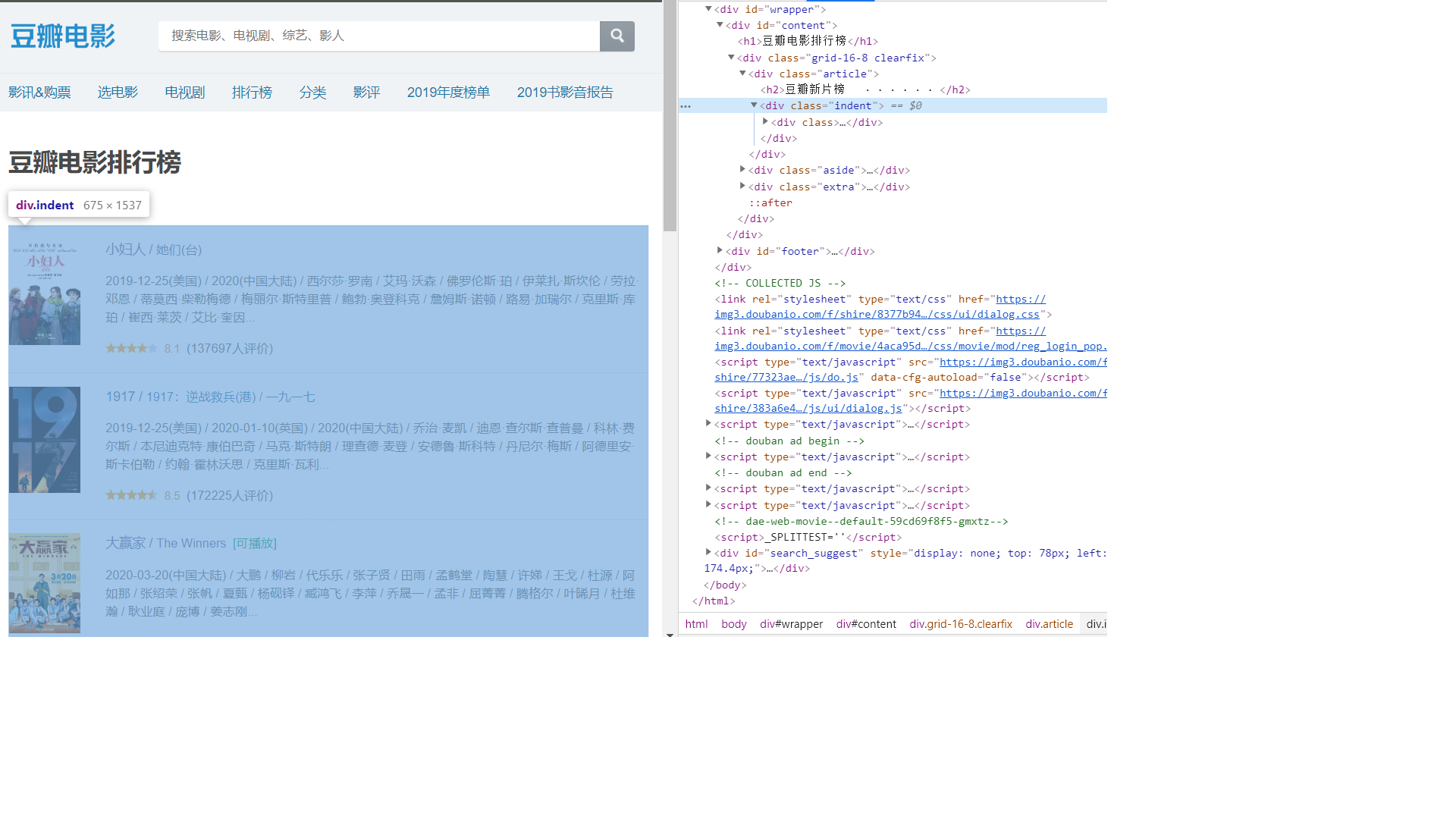
第一次筛选过后,我们可以看到,每一个电影都被一个名为table的标签所包裹,于是乎,根据下面的foreach,不难推测的出我们第二次选取的是每个独立电影的标签。
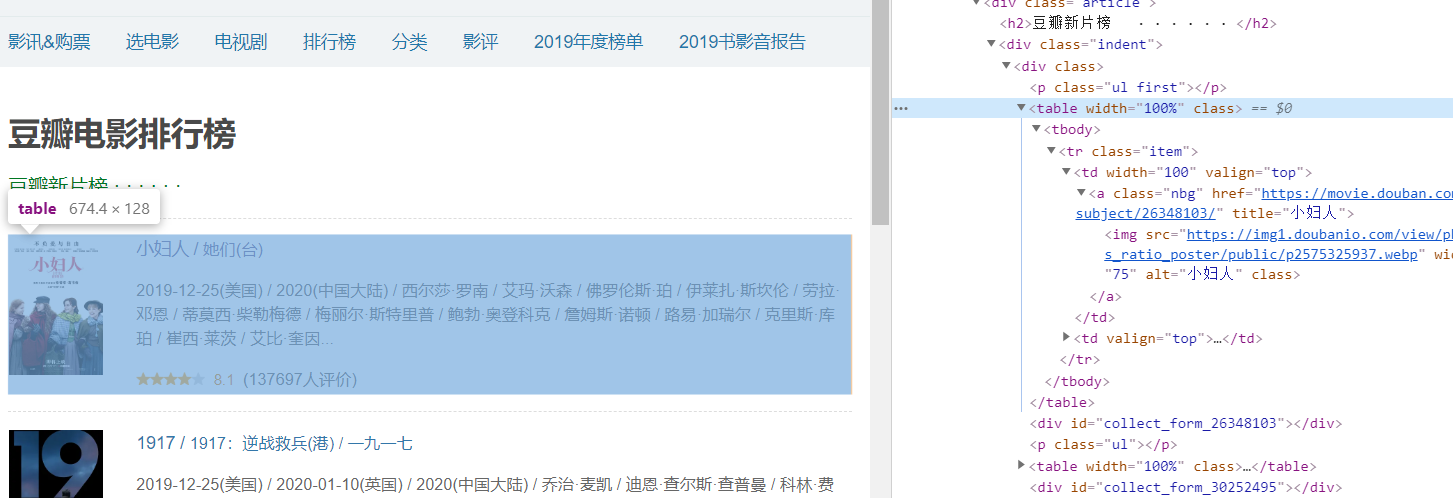
第二是筛选过后,剩下来的就是一个独立电影模块的所有内容了之后再不断利用select来选择标签,选出自己想要的内容。我们可以在选到了最后想要的标签后,使用attr(“abs:src”) ,来获取这个标签内的内容。当然,如果是文字内容的话,则使用 .text()。
————————————
下面是我实际操作的用来补充数据库的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| @Test
void add(){
String q="鞋子";
String url="http://www.shihuo.cn/running/list?page_size=60&scene=跑步鞋&sort=hot&c=跑鞋#qk=shaixuan";
Document doc = null;
try {
doc = Jsoup.connect(url).userAgent("Mozilla").get();
} catch (IOException e) {
e.printStackTrace();
}
Elements div = doc.getElementsByClass("list-main");
Elements ul = div.select("ul.list-ul");
Elements lis = ul.select("li");
int count=0;
for (Element li : lis) {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
Product product=new Product();
Elements img=li.select("img");
String imgUrl = img.get(0).attr("abs:src");
product.setImg(imgUrl);
Elements title=li.select("a");
product.setProductName(title.get(1).text());
String price=li.select("b").get(0).text();
product.setPrice(Double.parseDouble(price.substring(1,price.length())));
product.setCategory(q);
product.setNote("一双"+q);
product.setStock(100);
productService.add(product);
count++;
if (count==50){
break;
}
}
}
|
这段代码不做补充说明,但是可以作为第二个阶段,供给大家学习。
踩坑
当这个爬虫,遇到类出现空格的时候,getbyclass就不管用了,这时候需要使用:
1
| Elements div = doc.getElementsByAttributeValue("class","gl-warp clearfix");
|
来实现我们的获取class方法
