Redis在SpringBoot中的一些特殊用法 Redis除了操作那些数据类型的功能外,还能支持事务、流水线、发布订阅和Lua脚本等功能,这也是Redis常用的功能。在高并发的场景中,往往我们需要保证数据的一致性,这时考虑使用Redis务或者利用Redis执行Lua的原子性来达到数据一致性的目的,所以这里让我们对它们展开讨论。需要大批量执行Redis命令的时候,我们可以使用流水线来执行命令,这样可以极大地提Redis执行的速度。
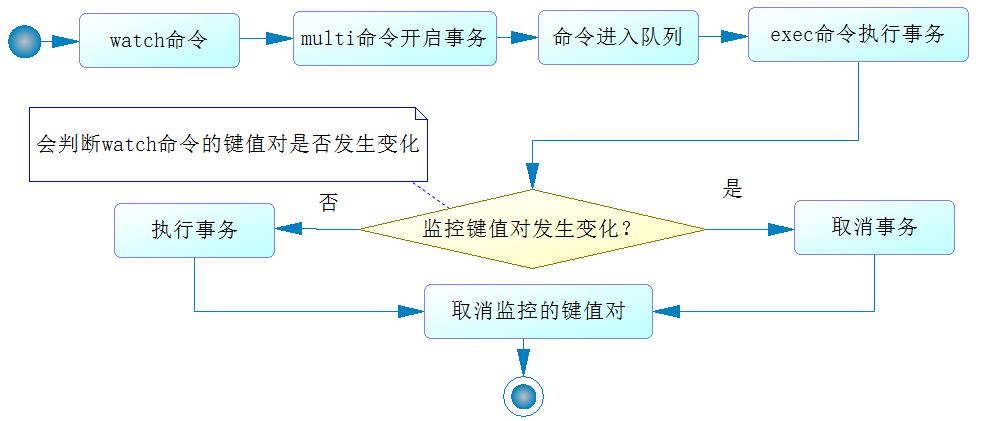
Redis事务 首先Redis是支持一定事务能力的NoSQL,在Redis中使用事务,通常的命令组合是watch…multi…exec,也就是要在一个Redis连接中执行多个命令,这时我们可以考虑使用SessionCallback接口来达到这个目的。
其中,watch命令是可以监控Redis的一些键multi命令是开始事务,开始事务,该客户端的命令不会马上被执行,而是存放在一个队列里,这点是需要注意的地方,也就是在这时我们执行一些堪回数据的命令,Redis也是不会马上执行的,而是把命令放到一个队列里,所以时调用Redis的命令,结果都是返回null,这是初学者容易犯的错误:exe命令的意义在于执行事,只是它在队列命令执行前会判断被watch监控的Redis的键的数据是否发生过变化(即使赋予与前相同的值也会被认为是变化过〉,如果它认为发生了变化,那么Redis就会取消事务,否则就会行事务,Redis在执行事务时,要么全部执行,要么全部不执行,而且不会被其他客户端打断,这就保证了Redis事务下数据的一致性。
如图,这就是Redis事务的执行流程:
下面我们来测试一下这个过程:
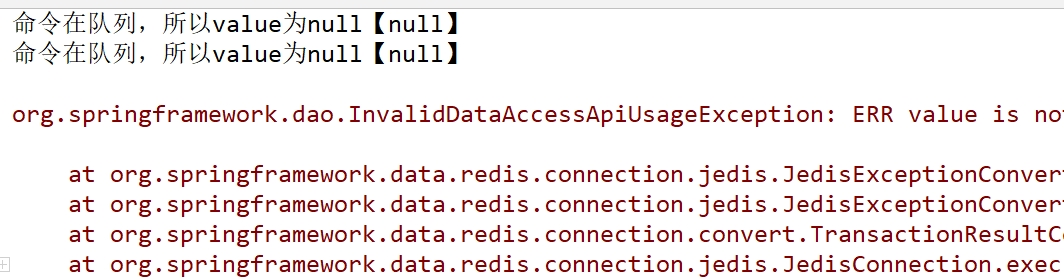
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Test void test1 () redisTemplate.opsForValue().set("key1" ,"value1" ); List list = (List) redisTemplate.execute((RedisOperations operations) -> { operations.watch("key1" ); operations.multi(); operations.opsForValue().set("key2" , "value2" ); operations.opsForValue().increment("key1" , 1 ); Object value2 = operations.opsForValue().get("key2" ); System.out.println("命令在队列,所以value为null【" + value2 + "】" ); operations.opsForValue().set("key3" , "value3" ); Object value3 = operations.opsForValue().get("key3" ); System.out.println("命令在队列,所以value为null【" + value3 + "】" ); return operations.exec(); }); System.out.println(list); }
我们来做两种测试:
1:在Redis客户端清空key2和key3两个键的数据,然后在②处设置断点,在调试的环境下让请求达到断点,此时在Redis上修改keyl的值,然后再跳过断点,在请求完成后在Redis上查询key2和key3值,可以发现key2、key3返回的值都为空(nil),因为程序中先使得Redis的watch命令监控了keyl的值,而后的multi让之后的命令进入队列,而在exec方法运行前我们修改了keyl,根据Redis事务的规则,它在exec方法后会探测keyl是否被修改过,如果没有则会执行事务,否则就取消事务,所以key2和key3没有被保存到Redis服务器中。
测试结果:
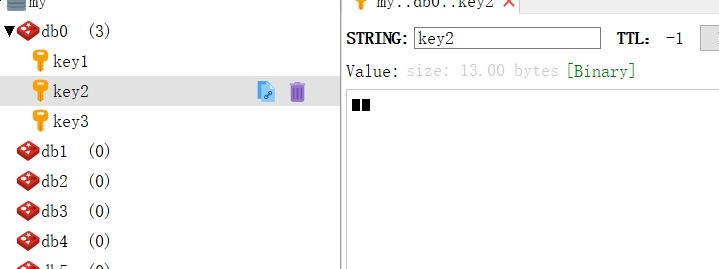
2:续把key2和key3两个值清空,把①处的注释取消,让代码可以运行,因为key1是一个字符串,所以这里的代码是对字符串加一,这显然是不能运算的。同样地,我们运行这段代码后,可以看到服务器抛出了异常,然后我们去Redis服务器查询key2和key3,可以看到它们已经有了值。注意,这就是Redis事务和数据库事务的不一样,对于Redis事务是先让命令进入队列,所以一开始它并没有检测这个加一命令是否能够成功,只有在exec命令执行的时候,才能发现错误,对于出错的命令Redis只是报出错误,而错误后面的命令依旧被执行,所以key2和key3都存在数据,这就是Redis事务的特点,也是使用Redis事务需要特别注意的地方。为了克服这个问题,一般我们要在执行Redis事务前,严格地检查数据,以避免这样的情况发生。
测试结果:
使用Redis流水线 默认的情况下,Redis客户端是一条条命令发送给Redis服务器的,这样显然性能不高。在关系数据库中我们可以使用批量,也就是只有需要执行SQL时,才一次性地发送所有的SQL去执行,这样性能就提高了许多。对于Redis也是可以的,这便是流水线(pipline)技术,在很多情况下并不是Redis性能不佳,而是网络传输的速度造成瓶颈,使用流水线后就可以大幅度地在需要执行很多命令时提升Redis的性能。
接下来我们就来试试使用了SessionCallBack接口的,单流水线性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test void test2 () Long start = System.currentTimeMillis(); List list = (List) redisTemplate.executePipelined((RedisOperations operations) -> { for (int i = 1 ; i <= 100000 ; i++) { operations.opsForValue().set("pipeline_" + i, "value_" + i); String value = (String) operations.opsForValue().get("pipeline_" + i); if (i == 100000 ) { System.out.println("命令只是进入队列,所以值为空【" + value + "】" ); } } return null ; }); Long end = System.currentTimeMillis(); System.out.println("耗时:" + (end - start) + "毫秒。" ); }
测试结果:
这里还是沿用SessionCallback接口执行写入和读出各10万次Redis命令,只是修改为了Lambda表达式而己如果你的JDK达不到8的版本以上,那么只能采用匿名类的形式来改写这段代码了。
为了测试性能,这里记录了开始执行时间和结束执行时间,并且打出了耗时。在我的测试中,这10万次读写基本在300~600ms,大约平均值在400~500ms,也就是不到ls就能执行10万次读和写命令,这个速度还是十分快的。在使用非流水线的情况下,我的测试大约每秒只能执行2~3万条命令,可见使用流水线后可以提升大约10倍的速度,它十分适合大数据量的执行。
但是需要注意以下两点:
此代码只是运用于测试,在运行如此多的命令时,需要考虑的另外一个问题是内存空间的消耗,因对于程序而言,它最终会返一个List象,如果过的命令执行返回的结果都保存到这个List中,显然会造成内存消耗过大,尤其在那些高并发的网站中就很容易造成川、内存溢出的异常,这个时候应该考虑使用迭代的方法执行Redis命令。
与事务一样,使用流水线的过程中,有的命令也只是进入队列而没有执行,所以执行的命令返回值也为空,这也是需要注意的地方。
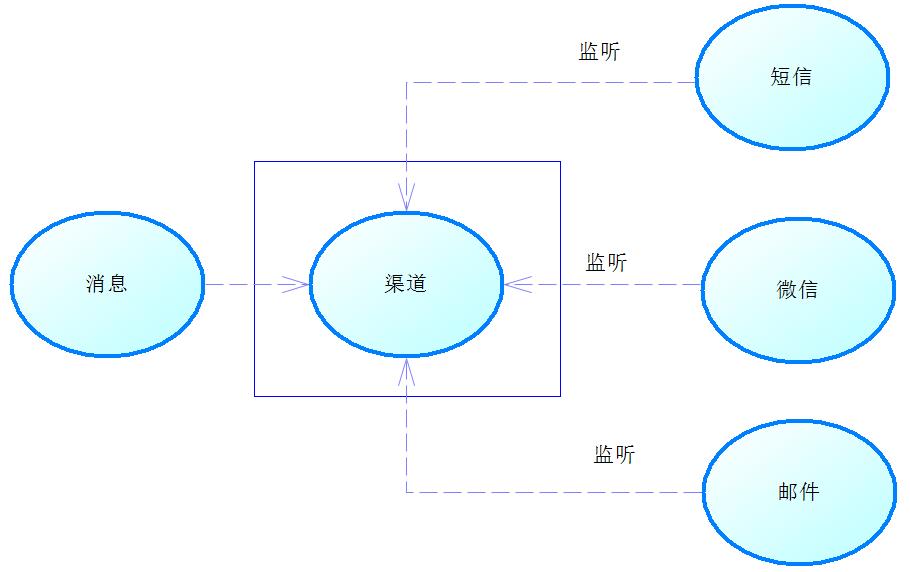
使用Redis发布订阅 发布订阅是消息的一种常用模式。例如,在企业分配任务之后,可以通过邮件、短信或者微信通知到相关的责任人,这就是一种典型的发布订阅模式。首先是Redis提供一个渠道,让消息能够发送到这个渠道上,而多个系统可以监听这个渠道,如短信、微信和邮件系统都可以监昕这个渠道,当一条消息发送到渠道,渠道就会通知它的监昕者,这样短信、微信邮件系统就能够得到这个渠道给它们的消息了,这些监听者会根据自己的需要去处理这个消息,于是我们就可以得到各种各样的通知了。
为了接收到Redis发送过来的消息,我们需要定义一个消息监听器:
1 2 3 4 5 6 7 8 9 10 11 12 @Component public class RedisMessageListener implements MessageListener @Override public void onMessage (Message message, byte [] pattern) String body = new String(message.getBody()); String topic = new String(pattern); System.out.println(body); System.out.println(topic); } }
这里的onMessage方法是得到消息后的处理方法,其中message参数代表Redis发送过来的消息,pattern是渠道名称,。且也在Message方法里打印了它们的内容。这里因为标注了@Component注解,所以在SpringBoot扫描后,会把它自动装配到IoC容器中。
此外,还需要监听容器的配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 @Component public class ListenerContainer @Autowired private RedisConnectionFactory connectionFactory = null ; @Autowired private MessageListener redisMsgListener = null ; private ThreadPoolTaskScheduler taskScheduler = null ; @Bean public ThreadPoolTaskScheduler initTaskScheduler () if (taskScheduler != null ) { return taskScheduler; } taskScheduler = new ThreadPoolTaskScheduler(); taskScheduler.setPoolSize(20 ); return taskScheduler; } @Bean public RedisMessageListenerContainer initRedisContainer () RedisMessageListenerContainer container = new RedisMessageListenerContainer(); container.setConnectionFactory(connectionFactory); container.setTaskExecutor(initTaskScheduler()); Topic topic = new ChannelTopic("topic1" ); container.addMessageListener(redisMsgListener, topic); return container; } }
这里RedisTemplate和RedisConnectionFactory象都是SpringBoot自动创建的,所以这里只是把它们注入进来,只需要使用@Autowired解即。然后定义了一个任务池,并设置了任务池大小为20,这样它将可以运行线程,井进行阻塞,等待Redis消息的传入。
接着再定义了一个Redis消息听的容器RedisMessageListenerContainer,并且往容器设置了Redis连接工厂和指定运行消息的线程池,定义了接收“topicl”渠道的消息,这样系统就可以监听Redis关于“topicl"渠道的消息了。
测试结果:
使用Lua脚本 Redis中有很多的命令,但是严格来说Redis提供的计算能力还是比较有限的。为了增强Redis计算能力,Redis在2.6版本后提供了Lua脚本的支持,而且执行Lua脚本在Redis中还具备原子性,所以在需要保证数据一致性的高并发环境中,我们也可以使用Redis的Lua语言来保证数据的一致性,且Lua脚本具备更加强大的运算功能,在高并发需要保证数据一致性时,Lua脚本方案比使用Redis自身提供的事务要更好一些。
在Redis中有两种运行Lua的方法,一种是直接发送Lua到Redis服务器去执行,另一种是先把Lua发送给Redis,Redis对Lua脚本进行缓存,然后返回一个SHAl的32位编码回来,之后只需要发送SHAl相关参数给Redis便可以执行了。这里需要解释的是为什么会存在通过32位编码执行的方法。如果Lua脚本很长,那么就需要通过网络传递脚本给Redis去执了,而现实的情况是网络的传递速度往往跟不上Redis的执行速度,所以网络就会成为Redis执行的瓶颈。如果只是传递32位编码参数,那么需要传递的消息就少了许多,这样就可以极大地减少网络传输的内容,从而提高系统的性能。
为了支持Redis的Lua脚本,Spring供了RedisScript接口,与此同时也有一个DefaultRedisScript实现类。让我们先来看看RedisScript接口的源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public interface RedisScript <T > String getSha1 () ; @Nullable Class<T> getResultType () ; String getScriptAsString () ; default boolean returnsRawValue () return this .getResultType() == null ; } static <T> RedisScript<T> of (String script) { return new DefaultRedisScript(script); } static <T> RedisScript of (String script, Class<T> resultType) { Assert.notNull(script, "Script must not be null!" ); Assert.notNull(resultType, "ResultType must not be null!" ); return new DefaultRedisScript(script, resultType); } static <T> RedisScript<T> of (Resource resource) { Assert.notNull(resource, "Resource must not be null!" ); DefaultRedisScript<T> script = new DefaultRedisScript(); script.setLocation(resource); return script; } static <T> RedisScript<T> of (Resource resource, Class<T> resultType) { Assert.notNull(resource, "Resource must not be null!" ); Assert.notNull(resultType, "ResultType must not be null!" ); DefaultRedisScript<T> script = new DefaultRedisScript(); script.setResultType(resultType); script.setLocation(resource); return script; } }
这里Spring会将Lua脚本发送到Redis服务器进行缓存,而此时Redis服务器会返回一个32位的SHAl编码,这时候通过getShal方法就可以得到Redis返回的这个编码了;getResultType方法是获取Lua脚本返回的Java类型getScriptAsString是返回脚本的字符串,以便我们观看脚本。
下面我们来测试一下吧:
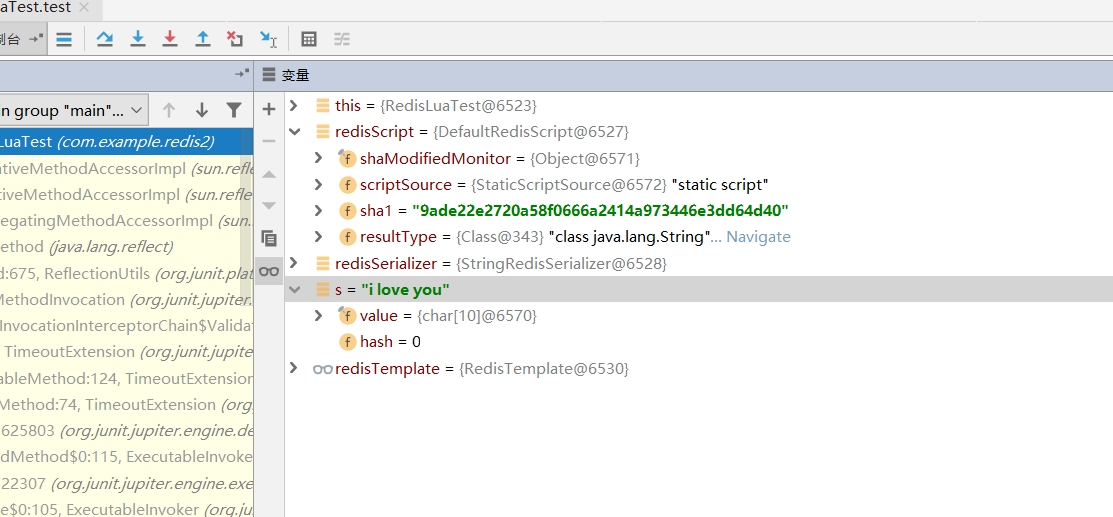
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Test void test () DefaultRedisScript<String> redisScript=new DefaultRedisScript<String >(); redisScript.setScriptText("return 'i love you'" ); redisScript.setResultType(String.class ) ; RedisSerializer<String > redisSerializer=redisTemplate.getStringSerializer(); String s=(String)redisTemplate.execute (redisScript,redisSerializer,redisSerializer,null ); System.out.println(); }
在最后一行打一个断点,开始测试:
这里的代码,首先Lua只是定义了一个简单的字符串,然后就返回了,而返回类型则定义为宇符串。这里必须定义返回类型,否则对于Spring不会把脚本执行的结果返回。接着获取了由RedisTemplate自动创建的字符串序列化器,而后使用RedisTemplate的execute方法执行了脚本。在RedisTemplate中,execute方法执行脚本的方法有两种,其定义如下:
1 2 3 4 5 6 7 public <T> T execute (RedisScript<T> script, List<K> keys, Object... args) { return this .scriptExecutor.execute(script, keys, args); } public <T> T execute (RedisScript<T> script, RedisSerializer<?> argsSerializer, RedisSerializer<T> resultSerializer, List<K> keys, Object... args) { return this .scriptExecutor.execute(script, argsSerializer, resultSerializer, keys, args); }
在这两个方法中,从参数的名称可以知道,script就是我们定义的RedisScript接口对象,keys代表Redis的键,args是这段脚本的参数。两个方法最大区别是一个存在序列化器的参数,另外个不存在。对于不存在序列化参数的方法,Spring将采用RedisTemplate提供的valueSerializer序列化器对传递的键和参进行序列化。这里我们采用了第二个方法调度脚本,并且设置为字符串序列化器,其中第一个序列化器是键的序列化器,二个是参数序列化器,这样键和参数就在字符串序列化器下被序列化了。
下面我们再来测试一下带参数的Lua吧:
这里的脚本中使用了两个键去保存两个参数,然后对这两个参数进行比较,如果相等则返回],否则返回0。注意脚本中kYS[l]和kYS[2]的写法,它们表客户端传递的第一个键和第二键,而ARGV[1]和ARGV[2则表示客户端传递第一个和第二个参数。
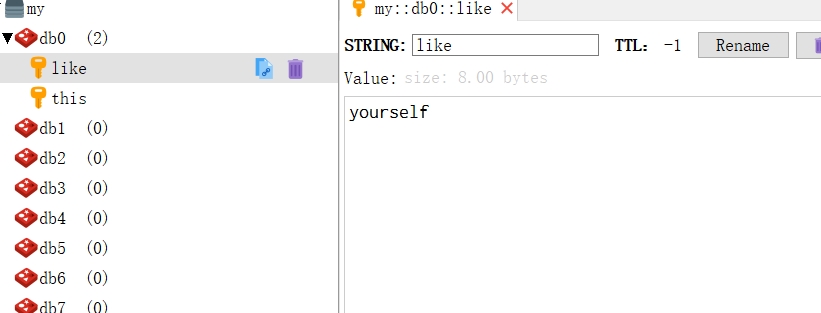
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Test void test2 () String key1="this" ,key2="like" ; String value1="not" ,value2="yourself" ; String lua="redis.call('set',KEYS[1],ARGV[1]) \n" +"redis.call('set',KEYS[2],ARGV[2]) \n" +"local str1=redis.call('get',KEYS[1]) \n" +"local str2=redis.call('get',KEYS[2]) \n" +"if str1==str2 then \n" +"return 1 \n" +"end \n" +"return 0 \n" ; System.out.println(lua); DefaultRedisScript<Long> redisScript=new DefaultRedisScript<Long>(); redisScript.setScriptText(lua); redisScript.setResultType(Long.class ) ; RedisSerializer<String> stringRedisSerializer=redisTemplate.getStringSerializer(); List<String> keyList =new ArrayList<>(); keyList.add(key1); keyList.add(key2); Long result=(Long) redisTemplate.execute (redisScript,stringRedisSerializer,stringRedisSerializer,keyList,value1,value2); }
这里使用keyList保存了各个键,然后通过Redis的execute方法传递,参数则可以使用可变化的方式传递,且设置了给键和参数的序列化器都为字符串序列化器,这样便能够运行这段脚本了。我们的脚本返回为一个数字,这里值得注意的是,因为Java会把整数当作长整型(Long),所以这里返回值设置为Long型。
测试结果: