Redis在SpringBoot中的基础实现
之前在讲SpringBoot整合Redis的时候,仅仅只是说了简单而又直观的运用,现在,我们来看看Redis在SpringBoot中,到底还有哪些操作。为此,我们仍然需要建立一个工程,其中的Redis使用的是Jedis驱动去连接,如图:
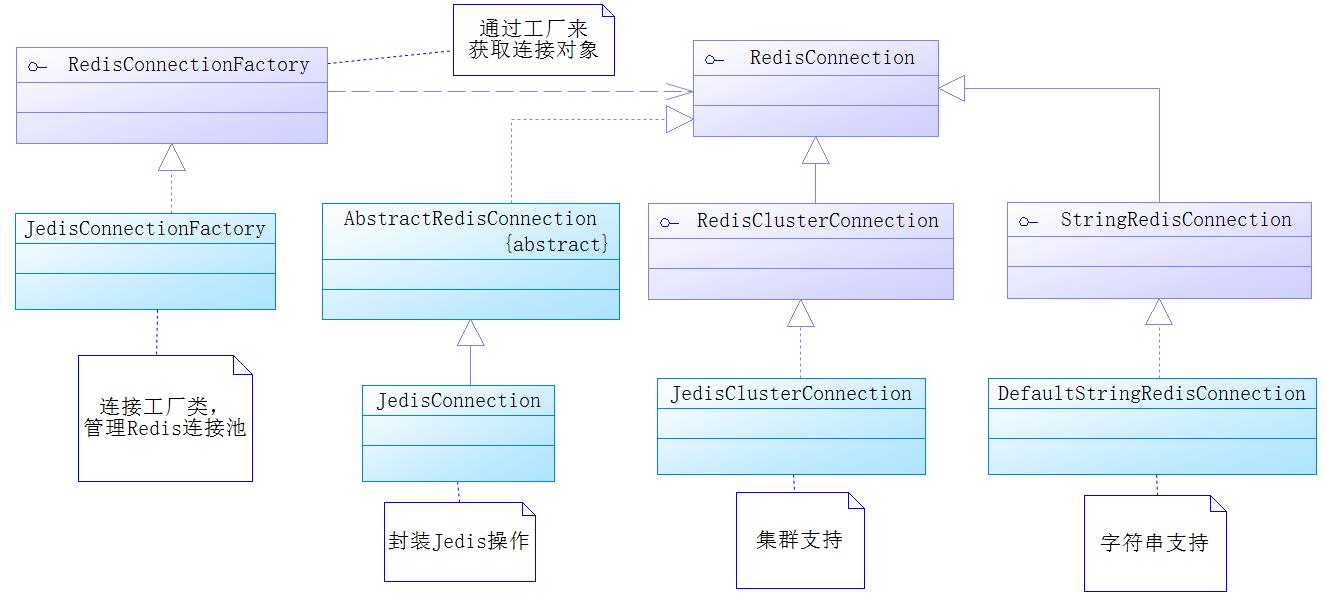
从图可以看出,在Spring中是通过RedisConnection接口操作Redis的,而RedisConnection则对原生的Jedis进行封装。要获取RedisConnection接口对象,是通过RedisConnectionFactory接口去生成的,所以第一步要配置的便是这个工厂了,而配置这个工厂主要是配置Redis的连接池,对于连接池可以限定其最大连接数、超时时间等属性。下面开发一个简单的RedisConnectionFactory接口对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| @Configuration
public class RedisConfig {
private RedisConnectionFactory connectionFactory = null;
@Bean(name = "redisConnectionFactory")
public RedisConnectionFactory initConnectionFactory() {
if (this.connectionFactory != null) {
return this.connectionFactory;
}
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(50);
poolConfig.setMaxTotal(100);
poolConfig.setMaxWaitMillis(2000);
JedisConnectionFactory connectionFactory = new JedisConnectionFactory(poolConfig);
RedisStandaloneConfiguration rsc = connectionFactory.getStandaloneConfiguration();
rsc.setHostName("localhost");
rsc.setPort(6379);
this.connectionFactory = connectionFactory;
return connectionFactory;
}
}
|
这就是Redis的配置,当然,你也可以在application.yml文件中把配置写入,由SpringBoot去自动完成,他们之间并没有什么区别。
RedisTemplate
我们在SpringBoot当中,所使用Redis最多的类是RedisTemplate,RedisTemplate是一个强大的类,首先它会自动从RedisConnectionFactory工厂中获取连接,然后执行对应的Redis命令,在最后还会关闭Redis的接。这些在RedisTemplate都被封装了,所以并不需要开发者关注Redis连接的闭合问题。
我们可以创建一个RedisTemplate:
1
2
3
4
5
6
| @Bean(name = "redisTemplate")
public RedisTemplate<Object,Object> init(){
RedisTemplate<Object,Object> redisTemplate=new RedisTemplate<>();
redisTemplate.setConnectionFactory(initConnectionFactory());
return redisTemplate;
}
|
可以从上述代码中得知,每当RedisTemplate需要被使用时,它就会创建一个工厂实例,去初始化这个RedisTemplate,让它获取这个连接的能力,可能很多人看到这里有点疑惑,为什么他们需要这么麻烦呢?直接拥有连接不就好了吗?别着急,其实它们这样做是为了进一步的解耦,使得我们的Redis连接不被固有化,同时,这样的行为还有定制的作用,为什么呢?接着往下看。
我们开始对这个Redis进行一个实验,来看看它们是否真的成功了。
1
2
3
4
5
6
7
| @Test
void contextLoads() {
ApplicationContext context=new AnnotationConfigApplicationContext(RedisConfig.class);
RedisTemplate redisTemplate=context.getBean(RedisTemplate.class);
redisTemplate.opsForValue().set("ket1","value1");
redisTemplate.opsForHash().put("hash","field","hvalue");
}
|
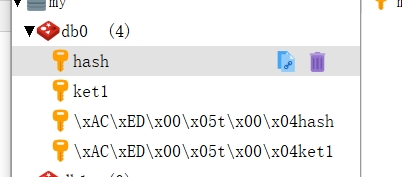
运行这段代码过后,我们可以从Redis控制台看到结果:

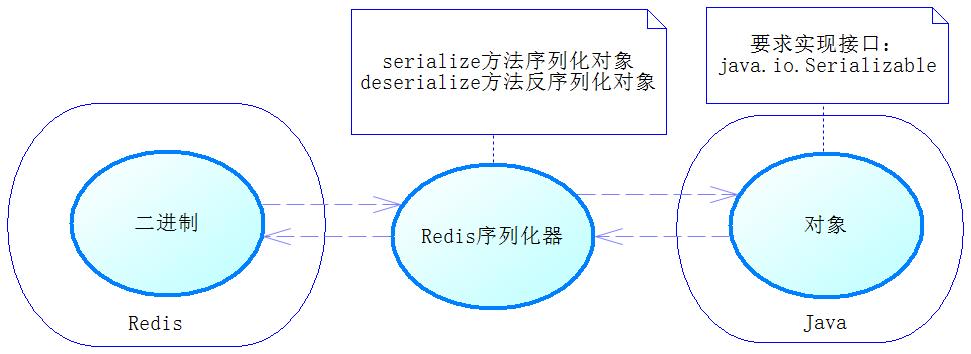
我想很多人一定很疑惑,为什么它们的键值,是这样的呢?这是因为,Redis是一种基于字符串存储的NoSQL,而Java是基于对象的语言,熟悉Java虚拟机的都知道,一个对象包含的东西太多了,包括了对象头等等,非常复杂的事物,所以无法直接被转化为字符串,而这并不是没有办法,只要类实现了java.io.Serializable接口,就能将类的对象序列化,通过这个原理,也能够反序列化。
于是乎,我们便可以在Redis中,实现序列化器:
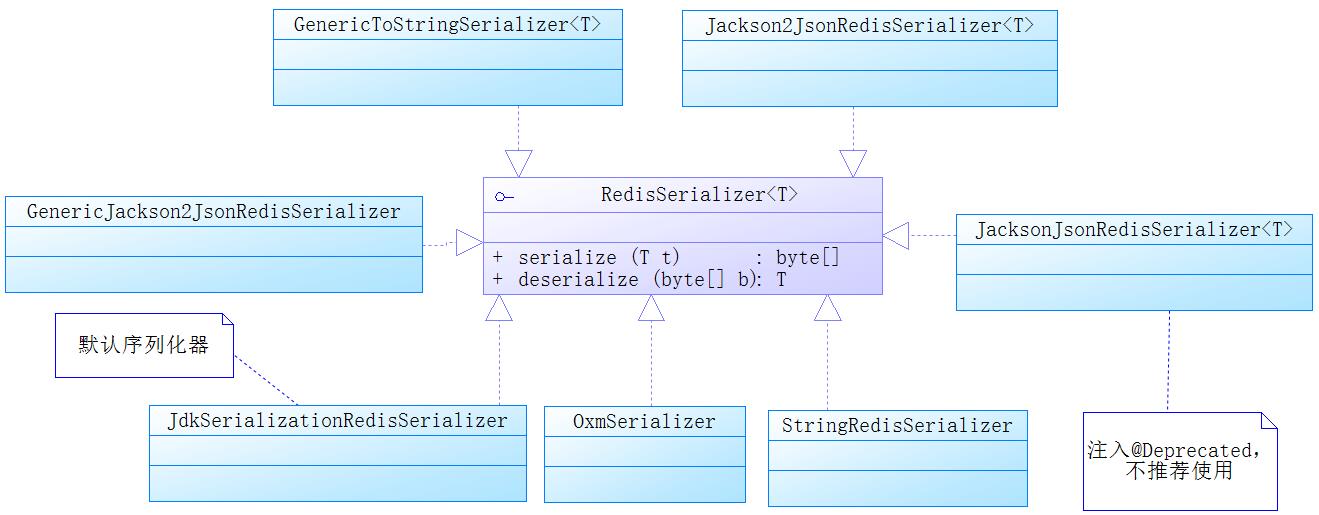
对于序列化器,Spring提供了RedisSerializer接口,它有两个方法。这两个方法,一个是serialize,它能把那些可以序列化的对象转换为二进制字符串;另一个是deserialize,它能够通过反序列化把二进制字符串转换为Java对象。图中的JacksonJsonRedisSerializer因为API过时,己经不推荐使用,我们这里主要讨论StringRedisSerializer和JdkSerializationRedisSerializer,其中JdkSerializationRedisSerializer是RedisTemplate默认的序列化器,代码清单的味etl”这个字符串就是被它序列化变为一个比较奇怪的宇符串的,原理如图:
RedisTemplate还有以下的属性可以配置:

所以,我们便可以在原来的代码当中,使用字符串序列化器:
1
2
3
4
5
6
7
8
9
10
| @Bean(name="redisTemplate")
public RedisTemplate<Object, Object> initRedisTemplate() {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(initConnectionFactory());
RedisSerializer<String> stringRedisSerializer = redisTemplate.getStringSerializer();
redisTemplate.setKeySerializer(stringRedisSerializer);
redisTemplate.setHashKeySerializer(stringRedisSerializer);
redisTemplate.setHashValueSerializer(stringRedisSerializer);
return redisTemplate;
}
|
实验结果:
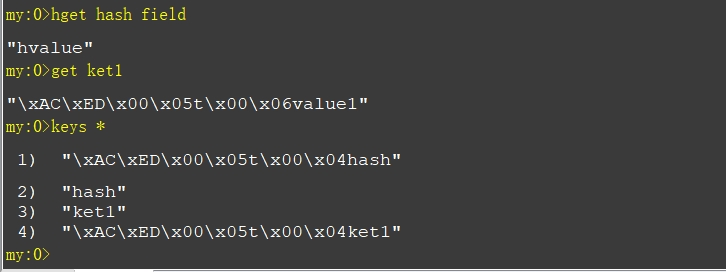
另外,我们可以从代码中看出一些值得注意的事情:
1
2
| redisTemplate.opsForValue().set("ket1","value1");
redisTemplate.opsForHash().put("hash","field","hvalue");
|
它们还存在一些值得我们探讨的细节。例如,上述的两个操作并不是在同一个Redis的连接下完成的,什么意思?让我们更加详细地阐述代码运行的过程,首先在操作ket1时,redisTemplate会先从连接工厂(RedisConnectionFactory)中获取一个连接,然后执行对应的Redis命令,再关闭这条连接,其次在操作hash时,它也是从连接工厂中获取另条连接,然后执行命令,再关闭该连接。所以我们可以看到这个过程是两条连接的操作,这样显然存在资源的浪费,我们更加希望是在同一连接中就执行两个命令。为了克服这个问题,Spring为我们提供了RedisCallback和SessionCallback个接口。不过在此之前我们需要了解Spring对Redis数据类型的封装。
Redis使用得最多的是字符串,因此在spring-data-redis项中,还提供了一个StringRedisTemplate,这个类继承RedisTemplate,只是提供了字符串的操作而己,对于复杂Java对象还需要自行处理。
SpringBoot对Redis数据类型操作的封装
Redis能够支持7种类型的数据结构,这7种类型是字符串、散列、列表(链表)、集合、有序集合、基数和地理位置。为此Spring针对每一种数据结构的操作都提供了对应的操作接口:
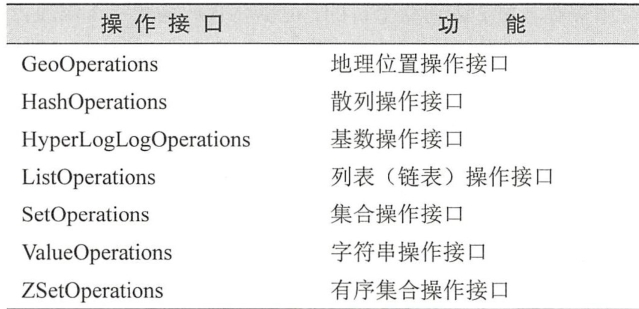
它们都可以通过RedisTemplate得到:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| //获取地理位置操作接口
redisTemplate.opsForGeo();
//获取散列操作接口
redisTemplateopsForHash();
//获取基数操作接口
redisTemplate.opsForHyperLogLog();
//获取列表操作接口
redisTemplate.opsForList();
//获取集合操作接口
redisTemplate.opsForSet();
//获取字符串操作接口
redisTemplate.opsForValue();
//获取有序集合操作接口
redisTemplate.opsForZSet();
|
这样就可以通过各类的操作接口来操作不同的数据类型了,当然这需要你熟悉Redis的各种命令。有时我们可能需要对某一个键值对(key”value)做连续的操作,例如,有时需要连续操作一个散列数据类型或者列表多次,这时Spring也提供支持,它提供了对应的BoundXXXOperations接口:

同样的,也有对应的方法:
1
2
3
4
5
6
7
8
9
10
11
12
| //获取地理位置绑定键操作接口
redisTemplate.boundGeoOps(”geo”);
//获取散列绑定键操作接口
redisTemplate.boundHashOps(”hash”);
//获取列表(链表)绑定键操作接口
redisTemplate.boundListops(”list");
//获取集合绑定键操作接口
redisTemplate.boundSetOps(”set”);
//获取字符串绑定键操作接口
redisTemplate.boundValueOps("string”),
//获取有序集合绑定键操作接口
redisTemplate.boundZSetOps(”zset");
|
获取其中的操作接口后,我们就可以对某个键的数据进行多次操作,这样我们就知道如何有效地通过Spring操作Redis的各种数据型了。
SessionCallback和RedisCallback接口
们的作用是让RedisTemplate进行回调,通过它们可以在同一条连接下执行多个Redis命令。其中SessionCallback提供了良好的封装,对于开发者比较友好,因此在实际的开发中应该优先选择使用它;相对而言,RedisCallback接口比较底层,需要处理的内容也比较多,可读性较差,所以在非必要的时候尽量不选择使用它。
1
2
3
4
5
6
7
8
9
10
11
12
|
public static void useRedisCallback(RedisTemplate redisTemplate) {
redisTemplate.execute(new RedisCallback() {
@Override
public Object doInRedis(RedisConnection rc)
throws DataAccessException {
rc.set("key1".getBytes(), "value1".getBytes());
rc.hSet("hash".getBytes(), "field".getBytes(), "hvalue".getBytes());
return null;
}
});
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public static void useSessionCallback(RedisTemplate redisTemplate) {
redisTemplate.execute(new SessionCallback() {
@Override
public Object execute(RedisOperations ro)
throws DataAccessException {
ro.opsForValue().set("key1", "value1");
ro.opsForHash().put("hash", "field", "hvalue");
return null;
}
});
}
|
上述代码中,我们采用了匿名类的方式去使用它们。从代码中可以看出,RedisCallback接口井不是那么友好,但是它能够改写一些底层的东西,如序列化的问题,所以在需要改写那些较为底层规则时,可以使用它。使用SessionCallback接口则比较友好,这也是我在大部分情况下推荐使用的接口,它提供了更为高级的API,使得我们的使用更为简单,可读性也更佳。如果采用的是Java8或者以上的版本,则还可以使用Lambda表达式改写上述代码,这样代码就会更加清爽。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public static void useRedisCallback(RedisTemplate redisTemplate) {
redisTemplate.execute((RedisConnection rc) -> {
rc.set("key1".getBytes(), "value1".getBytes());
rc.hSet("hash".getBytes(), "field".getBytes(), "hvalue".getBytes());
return null;
});
}
public static void useSessionCallback(RedisTemplate redisTemplate) {
redisTemplate.execute((RedisOperations ro) -> {
ro.opsForValue().set("key1", "value1");
ro.opsForHash().put("hash", "field", "hvalue");
return null;
});
}
|
之后,我们再清除掉所有缓存,重新测试一遍:
1
2
3
4
5
6
7
| AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(RedisConfig.class);
RedisTemplate redisTemplate = ctx.getBean(RedisTemplate.class);
useSessionCallback(redisTemplate);
ctx.close();
|
结果是成功的。
SpringBoot中使用Redis
虽然我们在整合Redis的时候,已经使用过注解了,但是这样的方法,并不能直观的学习到它的用法,于是乎,我们便一步一步的手动去操作一遍吧。
首先便是使用application.yml去代替Config:
1
2
3
4
5
6
7
8
9
10
11
| spring:
redis:
jedis:
pool:
min-idle: 5
max-active: 10
max-idle: 10
max-wait: 2000
port: 6379
host: localhost
timeout: 1000
|
这里我们配置了连接池和服务器的属性,用以连接Redis服务器,这样SpringBoot的自动装配机制就会读取这些配置来生成有关Redis的操作对象,这里它会自动生成RedisConnectionFactory、RedisTemplate、StringRedisTemplate等常用的Redis对象。我们知道,RedisTemplate会默认使用JdkSerializationRedisSerializer进行序列化键值,这样便能够存储到Redis服务器中。
如果这样,Redis服务器存入的便是一个经过序列化后的特殊字符串,有时候对于我们跟踪并不是很友好。如果我们在Redis只是使用字符串,那么使用其自动生成的StringRedisTemplate即可,但是这样就只能支持字符串了,并不能支持Java对象的存储。为了克服这个问题,可以通过设置RedisTemplate的序列化器来处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @Configuration
public class RedisTemplateConfig {
@Autowired
RedisTemplate redisTemplate=null;
@PostConstruct
public void init(){
initRedisTemplate();
}
private void initRedisTemplate() {
RedisSerializer serializer=redisTemplate.getStringSerializer();
redisTemplate.setKeySerializer(serializer);
redisTemplate.setHashKeySerializer(serializer);
}
}
|
首先通过@Autowired注入由SpringBoot根据配置生成的RedisTemplate对象,然后利用SpringBean生命周期的特性使用注解@PostConstruct自定义后初始化方法。在这个方法里,把RedisTemplate中的键序列化器修改为StringRedisSerializer。
因为之前我们讨论过,在RedisTemplate中它会默认地定义了一个StringRedisSerializer对象,所以这里我并没有自己创建一个新的StringRedisSerializer对象,而是从RedisTemplate中获取。然后把RedisTemplate关于键和其散列数据类型的filed都修改为了使用StringRedisSerializer进行序列化,这样我们在Redis服务器上得到的键和散列的field就都以宇符串存储了。
那么接下来,我们就在测试中,测试一下我们存储各种数据类型的情况吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| @Test
void test(){
redisTemplate.opsForValue().set("key1","value1");
redisTemplate.opsForValue().set("int_key","1");
stringRedisTemplate.opsForValue().set("int","1");
stringRedisTemplate.opsForValue().increment("int",1);
Jedis jedis=(Jedis)stringRedisTemplate.getConnectionFactory()
.getConnection().getNativeConnection();
jedis.decr("int");
Map<String,String> hash=new HashMap<>();
hash.put("field1","value1");
hash.put("field2","value2");
stringRedisTemplate.opsForHash().putAll("hash",hash);
stringRedisTemplate.opsForHash().put("hash","field3","value3");
BoundHashOperations hashOperations=stringRedisTemplate.boundHashOps("hash");
hashOperations.delete("field1","field2");
hashOperations.put("field4","value4");
}
|
这里的@Autowired注入了SpringBoot为我们自动初始化RedisTemplate和StringRedisTemplate对象。看到testStringAndHash法,先是存入了一个“key1”的数据,然后是“int_key”但是请注意这个“int_key”存入到Redis服务器中,因为采用了JDK序列化器,所以在Redis服务器中它不是整数,而是一个被JDK序列化器序列化后的二进制字符串,是没有办法使用Redis命令进行运算的。
为了克服这个问题,这里使用StringRedisTemplate对象保存了一个键为“int”的整数,这样就能够运算了。接着进行了加一运算,但是因为RedisTemplate并不能支持底层所有的Redis命令,所以这里先获取了原始的Redis连接的Jedis对象,用它来做减一运算。
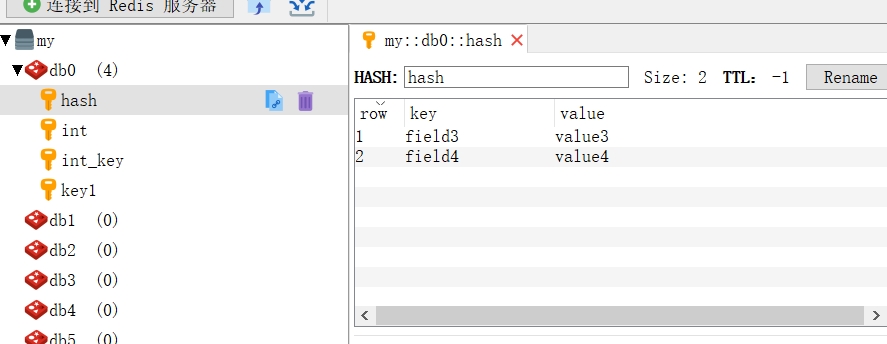
然后是操作散列数据类型,在插入多个散列的field时可以采用Map,然后为了方便对同一个数据操作,这里代码还获取了BoundHashOperations对象进行操作,这样对同一个数据操作就方便许多了。
测试结果如图:
列表也是常用的数据类型。在Redis中列表是一种链表结构,这就意味着查询性能不高,而增删节点的性能高,这是它的特性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Test
void test2(){
stringRedisTemplate.opsForList().leftPushAll("List1","v2","v4","v6","v8","v10");
stringRedisTemplate.opsForList().rightPushAll("List2","v1","v2","v3","v4","v5","v6");
BoundListOperations listOperations=stringRedisTemplate.boundListOps("List2");
Object result1=listOperations.rightPop();
Object result2=listOperations.index(1);
listOperations.leftPush("v0");
Long size=listOperations.size();
List elements=listOperations.range(0,size-2);
for (Object a:elements) {
System.out.println(a.toString());
}
}
|
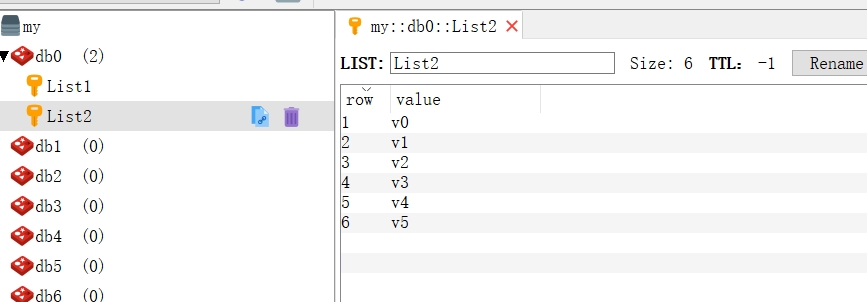
述操作是基于StringRedisTemplate的,所以保存到Redis服务器的都是字符串类型,只是这里有两点需要注意。首先是列表元素的顺序问题,是从左到右还是从右到左,这是容易弄糊涂的问题:其次是下标问题,在Redis中是以0开始的,这与Java中的数组类似。
测试结果:
接着是集合。对于集合,在Redis中是不允许成员重复的,它在数据结构上是一个散列表的结构,所以对于它而言是无序的,对于两个或者以上的集合,Redis还提供了交集、并集和差集的运算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| @Test
void test3(){
stringRedisTemplate.opsForSet().add("set1","v1","v1","v2","v3","v4","v5");
stringRedisTemplate.opsForSet().add("set2","v2","v4","v6","v8");
BoundSetOperations setOperations=stringRedisTemplate.boundSetOps("set1");
setOperations.add("v6","v7");
setOperations.remove("v1","v7");
Set set=setOperations.members();
Long size=setOperations.size();
setOperations.intersectAndStore("set2","inter");
setOperations.diff("set2");
setOperations.diffAndStore("set2","diff");
Set union=setOperations.union("set2");
setOperations.unionAndStore("set2","union");
}
|
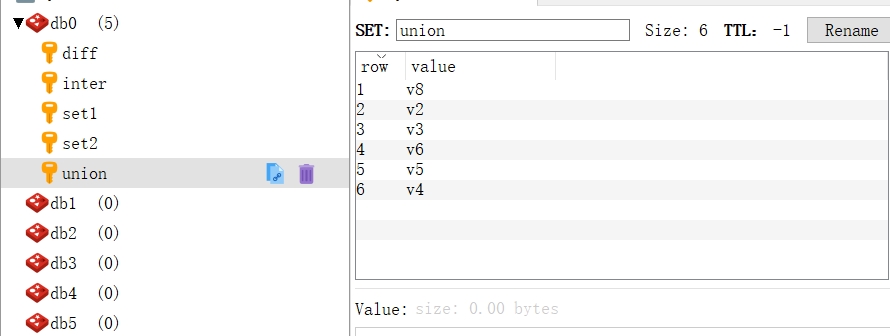
添加集合set1时,存在两个v1一样的元素。因为集合不允许重复,所以实际上在集合只算是一个元素。然后可以看到对集合各类操作,在最后还有交集、差集和并集的操作,这些是集合最常用的操作。
测试结果:
TypedTuple接口
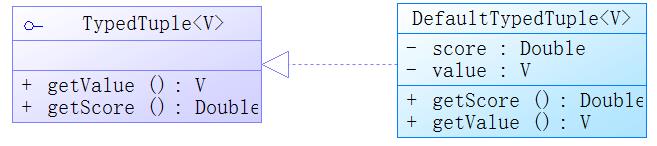
在一些网站中,经常会有排名,如最热门的商品或者最大的购买买家,都是常常见到的场景。对于这类排名,刷新往往需要及时,也涉及较大的统计,如果使用数据库会太慢。为了支持集合的排序,Redis还提供了有序集合(zset)。有序集合与集合的差异并不大,它也是一种散列表存储的方式,同时它的有序性只是靠它在数据结构中增加一个属性–score(分数)得以支持。为了支持这个变化,Spring提供了TypedTuple接口,它定义了两个方法,并且Spring还提供了其默认的实现类DefaultTypedTuple,如图:
在TypedTuple接口的设计中,value是保存有序集合的值,score则是保存分数,Redis是使用分数来完成集合的排序的,这样如果把买家作为一个有序集合,而买家花的钱作为分数,就可以使用Redis进行快速排序了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| @Test
void test4(){
Set<ZSetOperations.TypedTuple<String>> typedTuples=new HashSet<>();
for (int i = 1; i <=9 ; i++) {
double score=i*0.1;
ZSetOperations.TypedTuple<String> typedTuple=
new DefaultTypedTuple<String>("value"+i,score);
typedTuples.add(typedTuple);
}
stringRedisTemplate.opsForZSet().add("zset1",typedTuples);
BoundZSetOperations<String ,String > zSetOperations=
stringRedisTemplate.boundZSetOps("zset1");
zSetOperations.add("value10",0.26);
Set<String > setRange=zSetOperations.range(1,6);
Set<String > setScore=zSetOperations.rangeByScore(0.2,0.6);
RedisZSetCommands.Range range=new RedisZSetCommands.Range();
range.gt("value3");
range.lte("value8");
Set<String> setLex = zSetOperations.rangeByLex(range);
zSetOperations.remove("value9", "value2");
Double score = zSetOperations.score("value8");
Set<ZSetOperations.TypedTuple<String>> rangeSet = zSetOperations.rangeWithScores(1, 6);
Set<ZSetOperations.TypedTuple<String>> scoreSet = zSetOperations.rangeByScoreWithScores(1, 6);
Set<String> reverseSet = zSetOperations.reverseRange(2, 8);
}
|
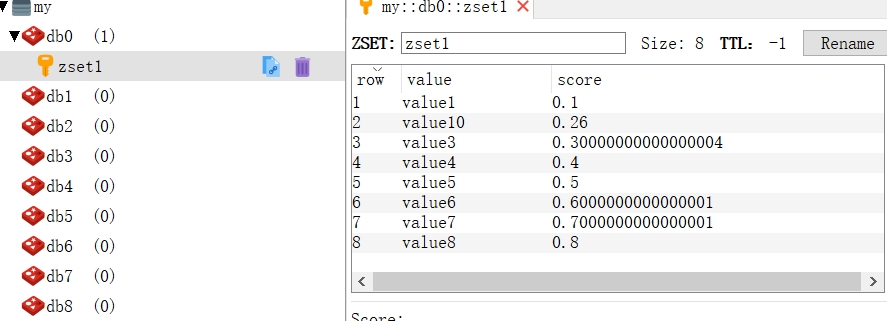
代码中使用了TypedTuple保存有序集合的元素,在默认的情况下,有序集合是从小到大地排序的,按下标、分数和值进行排序获取有序集合的元素,或者连同分数一起返回,有时候还可以进行从大到小的排序,只是在使用值排序时,我们可以使用Spring为我们创建的Range类,它可以定义值的范围,还有大于、等于、大于等于、小于等于等范围定义,方便我们筛选对应的元素。
测试结果: