
SpringBoot整合Swagger文档和Druid数据源
“你写的都是一堆垃圾代码!”
“你说的对,我走了,rm -rf /* “
Swagger文档
我们之前在对项目进行测试的时候,使用的都是PostMan,PostMan虽然提供了很多不同的测试接口以及类型,但是在使用的时候也需要很多的配置,写URL路径等等。而且,如果传过来的json数据过多,显然无法轻易的排查差错。
并且随着互联网技术的发展,现在的网站架构基本都由原来的后端渲染,变成了:前端渲染、先后端分离的形态,而且前端技术和后端技术在各自的道路上越走越远。
前端和后端的唯一联系,变成了API接口;API文档变成了前后端开发人员联系的纽带,变得越来越重要,swagger就是一款让你更好的书写API文档的框架。
所以,就有了Swagger文档这个框架,帮助我们快捷排查错误和API文档查看。
简介
历史
Swagger API项目由字典网站Wordnik的技术联合创始人[1] Tony Tam于2011年创建。在Wordnik产品的开发过程中,对API文档自动化和客户端SDK生成的需求成为造成挫败感的主要原因。Tam 基于REST架构风格的灵活性并使用为SOAP构建的许多工具功能,设计了API 的简单JSON表示形式协议。用户界面的概念由Ayush Gupta提出,他认为交互式用户界面将使希望“尝试”并根据API开发的最终用户受益。Ramesh Pidikiti领导了初始代码生成器的实现,而设计师/开发人员Zeke Sikilianos创造了Swagger这个名字。Swagger API项目于2011年9月成为开源项目。发布后不久,该项目中添加了许多新组件,包括独立的验证器,对Node.js的支持和Ruby on Rails。
在Swagger成立之初,小公司和独立开发商的吸引力不大。RESTful API通常没有机器可读的描述机制,而Swagger提供了一种简单且可发现的方式。Tam被邀请参加API行业一些思想领袖的会议,其中包括John Musser(ProgrammableWeb),Marsh Gardiner(Apigee,现在是Google产品),Marco Palladino(Kong)和Kin Lane(API传播者),讨论标准化工作。关于API说明。虽然会议没有为此制定具体计划,但它使Swagger成为了API领域的一项关键创新。
在使用Apache 2.0开源许可证的帮助下,许多产品和在线服务开始在其产品中包括Swagger,在Apigee,Intuit,Microsoft,IBM和其他开始公开认可Swagger项目的公司采用之后,这些产品和在线服务迅速加速。
在创建Swagger之后不久,便引入了用于描述RESTful API的替代结构,其中最受欢迎的是2013年4月的API Blueprint和2013 年9月的RAML。尽管这些竞争产品比Swagger具有更强的财务支持,但它们最初专注于Swagger的不同用例,截至2014年中,Swagger的兴趣增长速度超过了两者的结合[来源:Google趋势]。
2015年11月,维护Swagger的公司SmartBear Software宣布,它正在Linux基金会(称为OpenAPI Initiative)的赞助下,帮助创建一个新组织。包括Google,IBM和Microsoft在内的各种公司都是创始成员。[2]
在2016年1月1日,Swagger规范被重命名为OpenAPI规范,并被移至GitHub中的新存储库。虽然规范本身未更改,但重命名表示API描述格式和开源工具之间的区别。
根据托管存储库Sonatype和npm的数据,截至2017年7月,每天Swagger工具的下载量超过100,000次。
用法
Swagger的开源工具用法可以分为不同的用例:开发,与API的交互以及文档。
开发API
创建API时,可以使用Swagger工具根据代码本身自动生成Open API文档。这被非正式地称为代码优先或自底向上的API开发。尽管软件代码本身可以准确地表示Open API文档,但许多API开发人员[ 谁?]认为这是一种过时的技术,因为它在项目的源代码中嵌入了API描述,并且通常对于非开发人员来说很难做出贡献。
另外,使用Swagger Codegen,开发人员可以将源代码与Open API文档分离,并直接从设计中生成客户端和服务器代码。尽管被认为很复杂,但许多行业专家认为这是更现代的API工作流程[ 需要引用 ],并且通过延迟编码方面来设计API时具有更大的自由度。
与API交互
使用Swagger Codegen项目,最终用户可以直接从OpenAPI文档中生成客户端SDK,从而减少了对人工生成的客户端代码的需求。截至2017年8月,Swagger Codegen项目支持50多种不同语言和格式的客户端SDK生成。
文档API
当由OpenAPI文档描述时,可使用Swagger开源工具通过Swagger UI与API直接交互。该项目允许通过基于HTML的交互式用户界面直接连接到实时API 。可以直接从UI和界面用户探索的选项发出请求。
使用Swagger
在一个项目的pom文件中添加:
1 | <!-- swagger --> |
之后再写一个,由前端URL请求到后端的json数据,…….这里省略。
打开浏览器:
输入:
1 | http://localhost:8888/swagger-ui.html#/ |
可以得到一个Swagger页面:
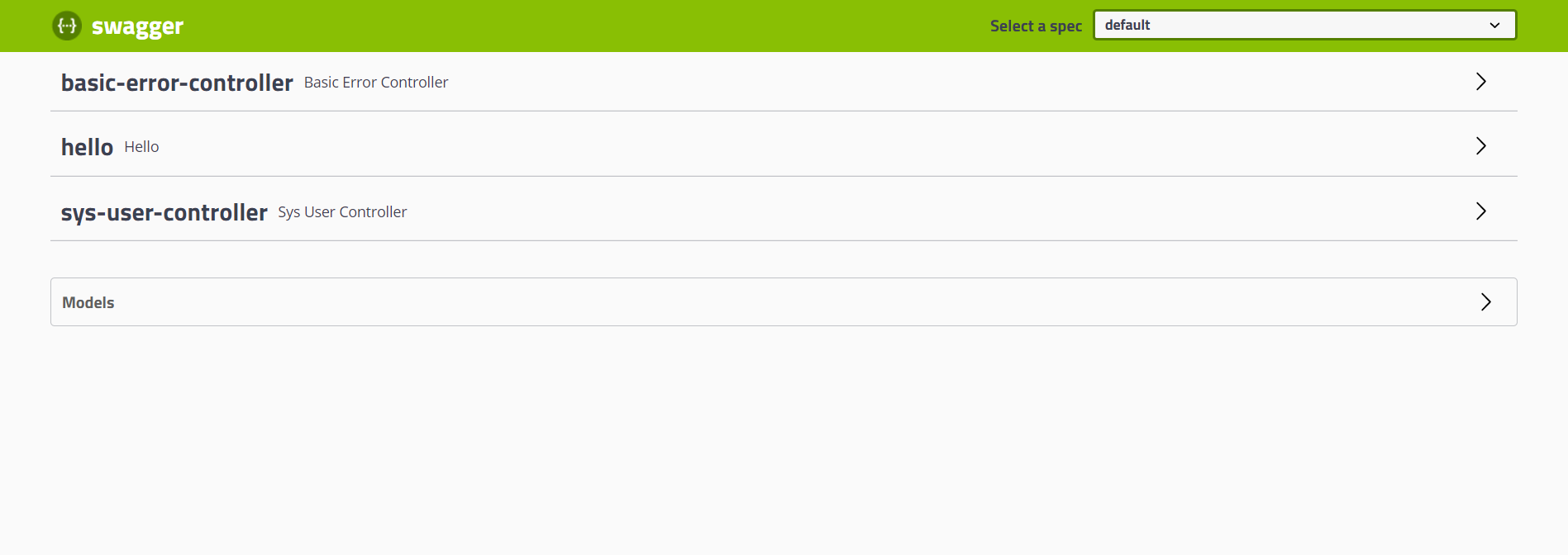
然后点击controller的一个方法,进行测试:
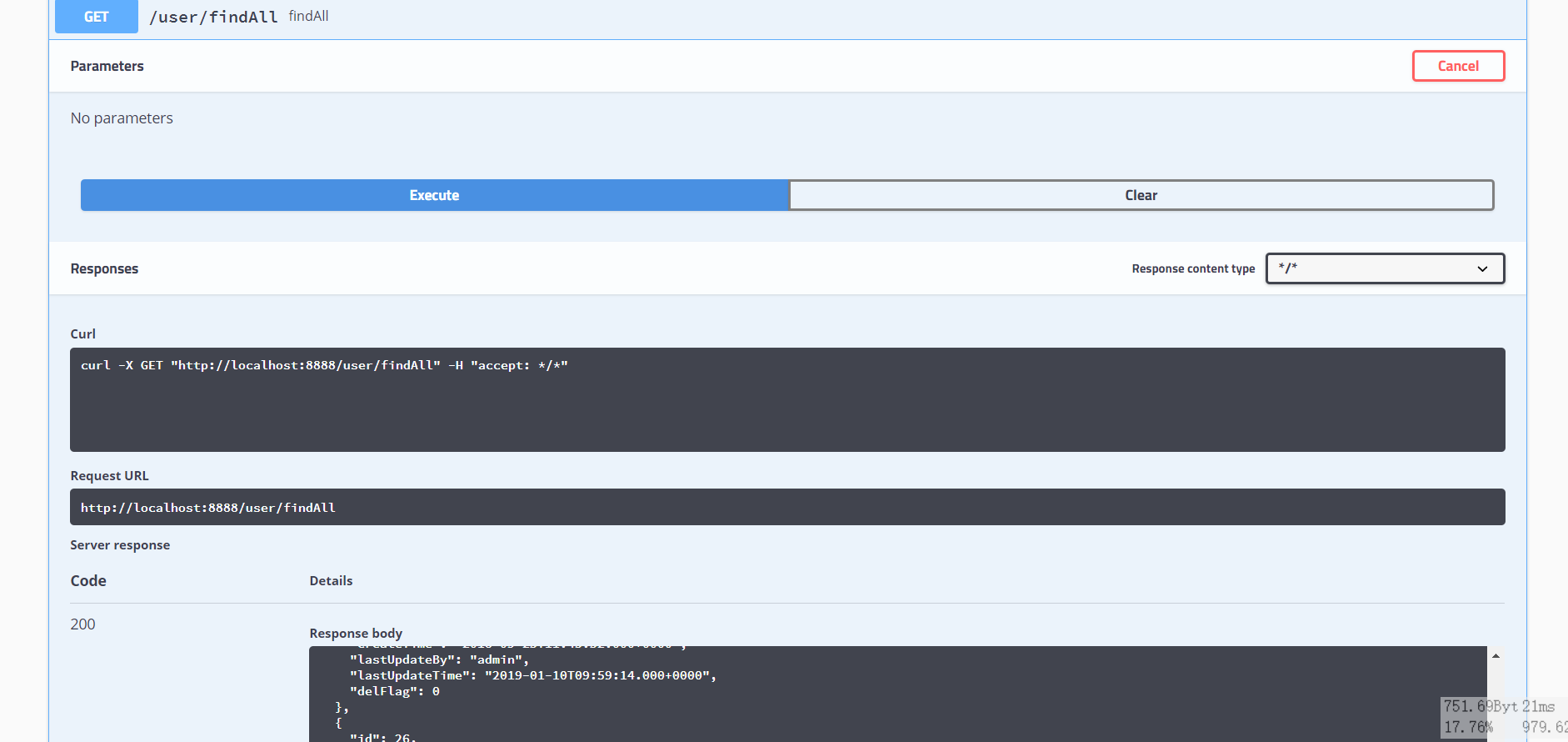
还能够看到各种状态信息
也可以选择各种的测试

Druid数据源
简介
druid,阿里巴巴数据库事业部出品,为监控而生的数据库连接池 。
它包括三部分:
- DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体系。
- DruidDataSource 高效可管理的数据库连接池。
- SQLParser 。
功能:
- 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
- 替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
- 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
- SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
- 扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件。
性能对比
| 功能类别 | 功能 | Druid | HikariCP | DBCP | Tomcat-jdbc | C3P0 |
|---|---|---|---|---|---|---|
| 性能 | PSCache | 是 | 否 | 是 | 是 | 是 |
| LRU | 是 | 否 | 是 | 是 | 是 | |
| SLB负载均衡支持 | 是 | 否 | 否 | 否 | 否 | |
| 稳定性 | ExceptionSorter | 是 | 否 | 否 | 否 | 否 |
| 扩展 | 扩展 | Filter | JdbcIntercepter | |||
| 监控 | 监控方式 | jmx/log/http | jmx/metrics | jmx | jmx | jmx |
| 支持SQL级监控 | 是 | 否 | 否 | 否 | 否 | |
| Spring/Web关联监控 | 是 | 否 | 否 | 否 | 否 | |
| 诊断支持 | LogFilter | 否 | 否 | 否 | 否 | |
| 连接泄露诊断 | logAbandoned | 否 | 否 | 否 | 否 | |
| 安全 | SQL防注入 | 是 | 无 | 无 | 无 | 无 |
| 支持配置加密 | 是 | 否 | 否 | 否 | 否 |
而我们Springboot默认使用的链接池是:HikariCP
我们可以自行选择,面对不同的场景,是否使用Druid。
使用Druid
首先先添加依赖:
pom.xml
1 | <!-- druid --> |
然后在yml中添加配置:
application.yml
1 | spring: |
stat:Druid内置提供一个StatFilter,用于统计监控信息。
wall:Druid防御SQL注入攻击的WallFilter就是通过Druid的SQL Parser分析。Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如说分库分表、审计等。
log4j:这个就是日志记录的功能,可以把sql语句打印到log4j供排查问题。
参数说明
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:”DataSource-“ + System.identityHashCode(this). 另外配置此属性至少在1.0.5版本中是不起作用的,强行设置name会出错。详情-点此处。 | |
| url | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里 | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxPoolPreparedStatementPerConnectionSize | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句,常用select ‘x’。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 | |
| validationQueryTimeout | 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| keepAlive | false (1.0.28) | 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。 |
| timeBetweenEvictionRunsMillis | 1分钟(1.0.14) | 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
| numTestsPerEvictionRun | 30分钟(1.0.14) | 不再使用,一个DruidDataSource只支持一个EvictionRun |
| minEvictableIdleTimeMillis | 连接保持空闲而不被驱逐的最小时间 | |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
自定义配置文件
可以自定义配置文件,对Druid进行自定义属性配置:
1 | (prefix = "spring.datasource.druid") |
配置Servlet和Filter
1 |
|
主要是注入属性和配置连接池相关的配置,如黑白名单,监控管理后台登录账户密码等。
@EnableConfigurationProperties:用于导入上一步的Druid配置信息
public ServletRegistrationBean
public FilterRegistrationBean
编译运行
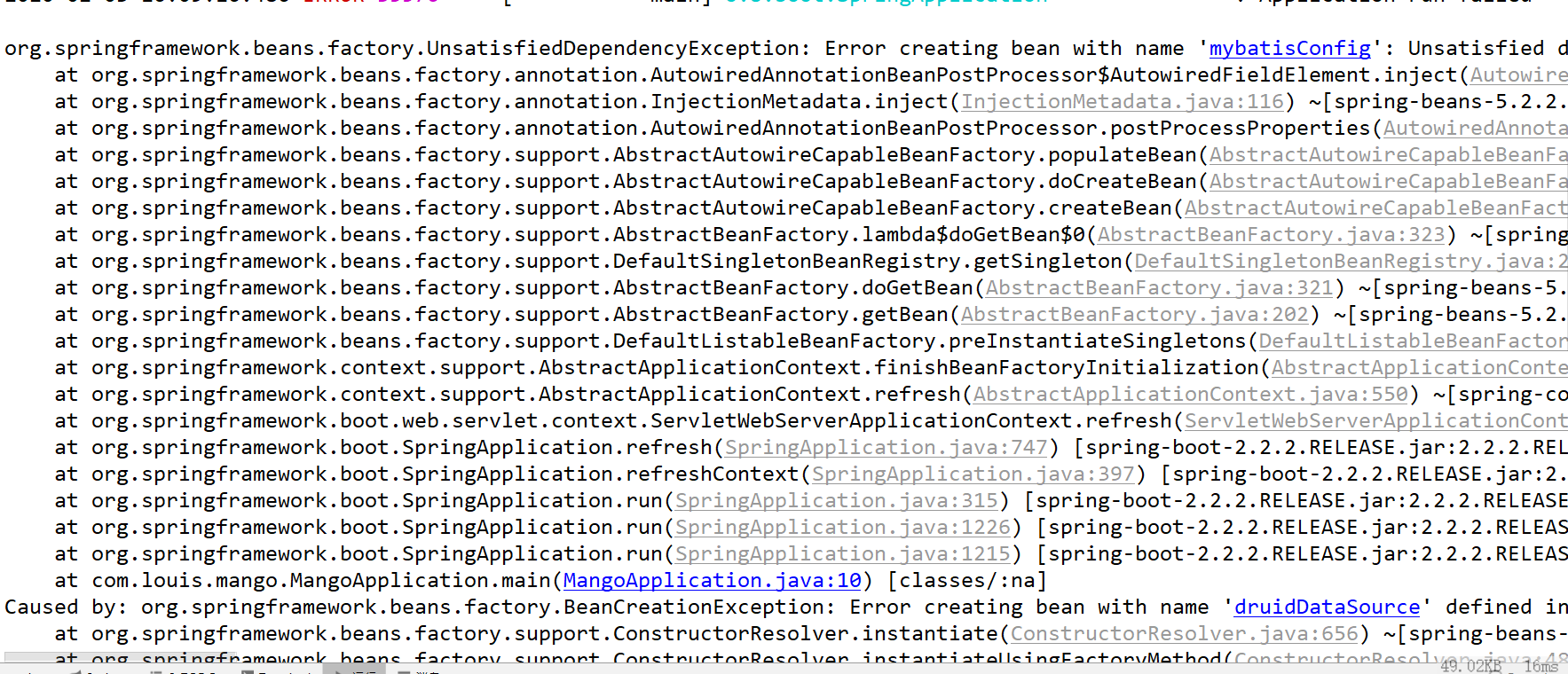
我们发现,编译出现了错误,根据错误信息,发现缺少了log4j依赖。
log4j
简介
Apache Log4j是一个基于Java的日志记录工具。它是由Ceki Gülcü首创的,现在则是Apache软件基金会的一个项目。 log4j是几种Java日志框架(英语:Java logging framework)之一。
Gülcü此后开创了SLF4J和Logback项目,意图成为log4j的继任者。
log4j团队创建了log4j的继任者,版本号为2.0的新版本。log4j 2.0着重于log4j 1.2、1.3、java.util.logging和logback中的问题,并解决这些框架中的架构问题。此外,log4j 2.0提供了一个插件架构,这使得其更可扩展。log4j 2.0不是与1.x向后兼容的版本[2],虽然有一个“适配器”可用
日志等级
下表中定义的log4j 1的日志级别和消息,以严重性递减排序。左栏列出了log4j的日志级别定义,右列提供了每个日志级别的简要说明。
| 级别 | 描述 |
|---|---|
| OFF | 最高级别,用于关闭日志记录。 |
| FATAL | 导致应用程序提前终止的严重错误。一般这些信息将立即呈现在状态控制台上。 |
| ERROR | 其他运行时错误或意外情况。一般这些信息将立即呈现在状态控制台上。 |
| WARN | 使用已过时的API,API的滥用,潜在错误,其他不良的或意外的运行时的状况(但不一定是错误的)。一般这些信息将立即呈现在状态控制台上。 |
| INFO | 令人感兴趣的运行时事件(启动/关闭)。一般这些信息将立即呈现在状态控制台上,因而要保守使用,并保持到最低限度。 |
| DEBUG | 流经系统的详细信息。一般这些信息只记录到日志文件中。 |
| TRACE | 最详细的信息。一般这些信息只记录到日志文件中。自版本1.2.12。 |
这里暂时不对log4j进行研究,先完成Druid的测试。
添加log4j.properties
先添加pom依赖:
1 | <!-- log4j --> |
在resource目录下建立一个log4j.properties文件,并添加:
1 | ### set log levels ### |
测试
在浏览器输入:
1 | http://localhost:8888/druid/login.html |
用户名和密码均为admin,登录
打开数据源页,可以看到数据源的配置信息
再输入http://localhost:8888/user/findAll,进行访问后,打开SQL监控页面:

我们可以从这里监控到每一次的SQL读取。
Druid除了拥有更好的性能之外,还能对SQL语句的进行进行更好的监控和管理。