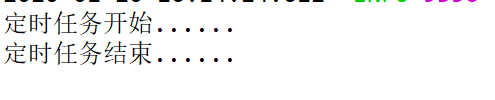高并发下抢购商品 这次做一个知识的总结,把之前所学习的mybatis、redis,rest、和并发编程相关的内容整合起来,模拟一个小型的场景。
这次场景叫做:抢购商品。我们在淘宝或者京东买东西的时候,偶尔某些商品会有一些打折期。这时候就有很多人去抢购商品,同时也是最考验我们数据库性能和后端设计的时候了。
设计与开发 数据库 先建立两个表,分别为产品表和订单表。
1 2 3 4 5 6 7 8 CREATE TABLE `springtest` .`t_product` ( `id` INT (12 ) NOT NULL AUTO_INCREMENT COMMENT '编号' , `product_name` VARCHAR (45 ) NOT NULL COMMENT '产品名称' , `stock` INT (10 ) NOT NULL COMMENT '库存' , `price` DECIMAL (16 ,2 ) NOT NULL COMMENT '单价' , `version` INT (10 ) NOT NULL DEFAULT 0 COMMENT '版本号' , `note` VARCHAR (256 ) NOT NULL COMMENT '备注' , PRIMARY KEY (`id` ));
订单表
1 2 3 4 5 6 7 8 9 10 CREATE TABLE `springtest` .`t_purchase_record` ( `id` INT (12 ) NOT NULL AUTO_INCREMENT COMMENT '编号' , `user_id` INT (12 ) NOT NULL COMMENT '用户编号' , `product_id` INT (12 ) NOT NULL COMMENT '产品编号' , `price` DECIMAL (16 ,2 ) NOT NULL COMMENT '价格' , `quantity` INT (12 ) NOT NULL COMMENT '数量' , `sum` DECIMAL (16 ,2 ) NOT NULL COMMENT '总价' , `purchase_date` TIMESTAMP NOT NULL DEFAULT now () COMMENT '购买日期' , `note` VARCHAR (512 ) NULL COMMENT '备注' , PRIMARY KEY (`id` ));
持久层开发 实体类 1 2 3 4 5 6 7 8 9 10 11 12 @Data @Alias ("product" )public class ProductPo implements Serializable private static final long serialVersionUID = 3288311147760635602L ; private Long id; private String productName; private int stock; private double price; private int version; private String note; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Data @Alias ("purchaseRecord" )public class PurchaseRecordPo implements Serializable private static final long serialVersionUID = -360816189433370174L ; private Long id; private Long userId; private Long productId; private double price; private int quantity; private double sum; private Timestamp purchaseTime; private String note; }
这里接入了 Serializable,之所以要这么做,是为了序列化 。
什么情况下需要序列化?
a)当你想把的内存中的对象写入到硬盘的时候;
b)当你想用套接字在网络上传送对象的时候;
c)当你想通过RMI传输对象的时候
总的就是说安全性问题,具体原因见解释:假如没有一个接口(即没有Serializable来标记是否可以序列化),让所有对象都可以序列化。那么所有对象通过序列化存储到硬盘上后,都可以在序列化得到的文件中看到属性对应的值(后面将会通过代码展示)。所以最后为了安全性(即不让一些对象中私有属性的值被外露),不能让所有对象都可以序列化。要让用户自己来选择是否可以序列化,因此需要一个接口来标记该类是否可序列化。。
最重要的两个原因是:
xml设计 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace ="com.example.designshop.dao.ProductDao" > <select id ="getProduct" parameterType ="long" resultType ="product" > select id, product_name as productName, stock, price, version, note from t_product where id=#{id} </select > <update id ="decreaseProduct" > update t_product set stock = stock - #{quantity}, version = version +1 where id = #{id} </update > </mapper >
1 2 3 4 5 6 7 8 9 10 11 12 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace ="com.example.designshop.dao.PurchaseRecordDao" > <insert id ="insertPurchaseRecord" parameterType ="purchaseRecord" > insert into t_purchase_record( user_id, product_id, price, quantity, sum, purchase_date, note) values(#{userId}, #{productId}, #{price}, #{quantity}, #{sum}, now(), #{note}) </insert > </mapper >
dao层 1 2 3 4 5 6 7 8 9 @Mapper public interface ProductDao public ProductPo getProduct (Long id) public int decreaseProduct (@Param("id" ) Long id, @Param ("quantity" ) int quantity) }
1 2 3 4 @Mapper public interface PurchaseRecordDao public int insertPurchaseRecord (PurchaseRecordPo pr) }
配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 mybatis: mapper-locations: classpath:/mapper/*.xml type-aliases-package: com.example.designshop.pojo spring: datasource: username: root password: 123456 url: jdbc:mysql://localhost:3306/springtest?useSSL=false&serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8 driver-class-name: com.mysql.cj.jdbc.Driver tomcat: max-idle: 10 max-wait: 10000 max-active: 50 initial-size: 5 # 隔离级别为读写提交 default-transaction-isolation: 2 server: port: 8888
隔离级别涉及到数据库事务相关,譬如脏读可重复读等待,以后会讲。
服务层 1 2 3 4 5 6 7 8 9 public interface PurchaseService public boolean purchase (Long userId, Long productId, int quantity)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Service public class PurchaseServiceImpl implements PurchaseService @Autowired private ProductDao productDao = null ; @Autowired private PurchaseRecordDao purchaseRecordDao = null ; @Override @Transactional public boolean purchase (Long userId, Long productId, int quantity) ProductPo product = productDao.getProduct(productId); if (product.getStock() < quantity) { return false ; } productDao.decreaseProduct(productId, quantity); PurchaseRecordPo pr = this .initPurchaseRecord(userId, product, quantity); purchaseRecordDao.insertPurchaseRecord(pr); return true ; } private PurchaseRecordPo initPurchaseRecord (Long userId, ProductPo product, int quantity) PurchaseRecordPo pr = new PurchaseRecordPo(); pr.setNote("购买日志,时间:" + System.currentTimeMillis()); pr.setPrice(product.getPrice()); pr.setProductId(product.getId()); pr.setQuantity(quantity); double sum = product.getPrice() * quantity; pr.setSum(sum); pr.setUserId(userId); return pr; } }
这里很明显的可以看到,我们从Dao层读取数据,看看是否还有库存,如果库存不足,则直接返回false,否则进行扣减库存,并且更新订单表。
控制层 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 @RestController public class PurchaseController @Autowired PurchaseService purchaseService = null ; @GetMapping ("/test" ) public ModelAndView testPage () ModelAndView mv = new ModelAndView("test" ); return mv; } @PostMapping ("/purchase" ) public Result purchase (Long userId, Long productId, Integer quantity) boolean success = purchaseService.purchase(userId, productId, quantity); String message = success ? "抢购成功" : "抢购失败" ; Result result = new Result(success, message); return result; } @Data class Result private boolean success = false ; private String message = null ; public Result () } public Result (boolean success, String message) this .success = success; this .message = message; } } }
控制层从从服务层调用方法,并且将数据装进响应结果里面。可以从控制层看到的是,我们是通过result传达信息到前端的。
Html 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" > <title > Title</title > <script type ="text/javascript" src ="https://code.jquery.com/jquery-3.2.1.min.js" > </script > </head > <script type ="text/javascript" > var params = { userId : 1, productId : 1, quantity : 3 }; $.post("./purchase" , params, function (result ) alert(result.message); }); </script > <body > <h1 > 测试</h1 > </body > </html >
前端会使用post方法,去请求后端,执行方法。
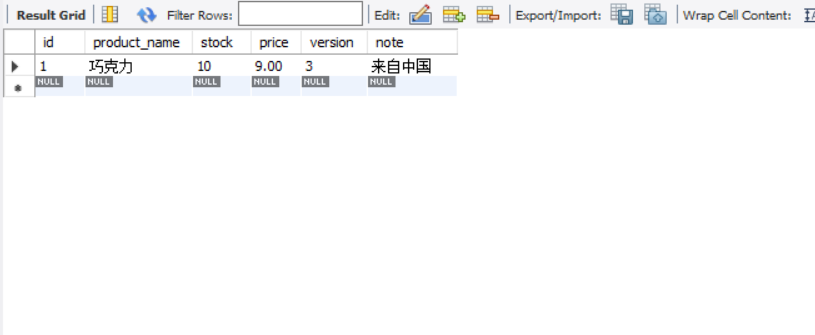
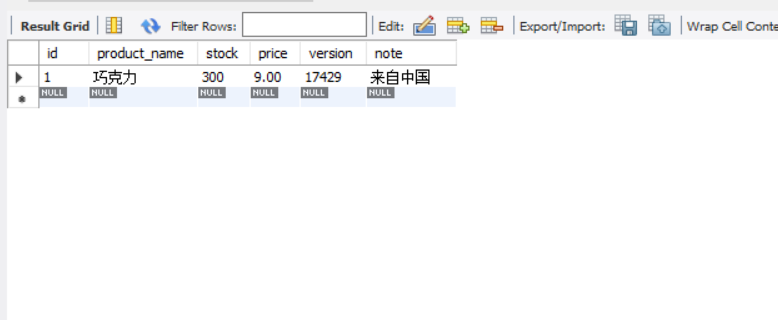
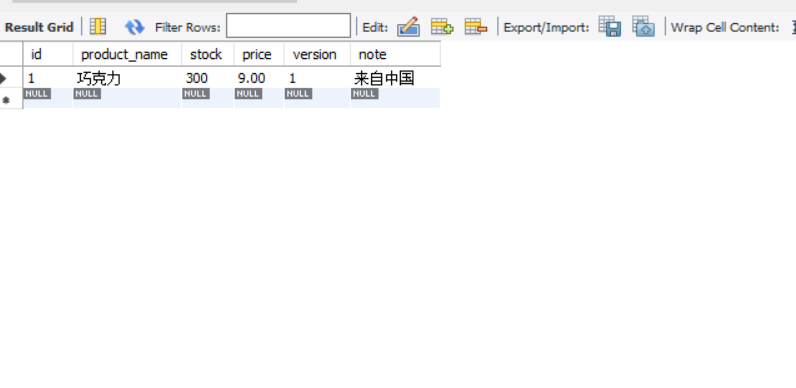
测试 这是数据库库存:
在网页输入 http://localhost:8888/test
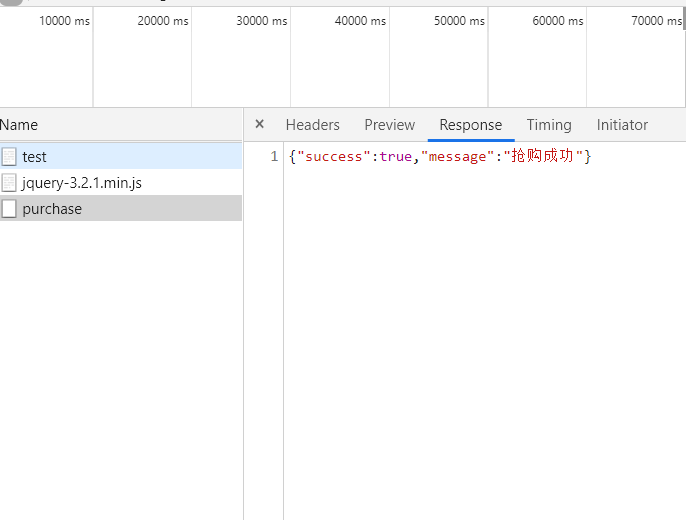
测试结果:
抢购成功!
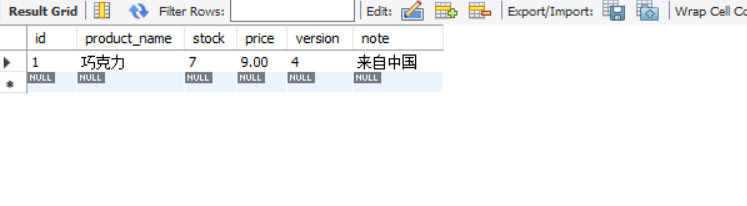
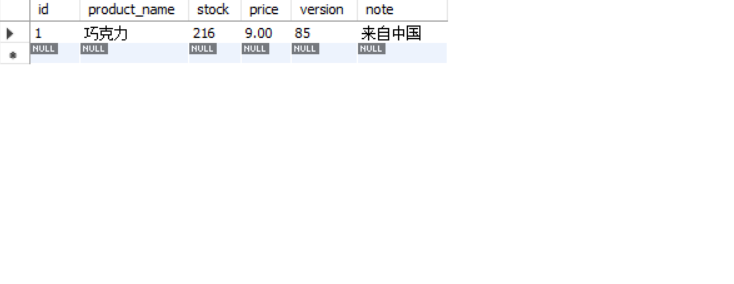
回看数据库:
高并发情况下 500次抢购 上面的例子仅仅是在一个单例进行的测试,那么,在高并发情况下,有着很多很多的请求呢?
我们假设有300的库存:
在html页面设置 500次抢购:
1 2 3 4 5 6 7 8 9 10 for (var i=1; i<=500; i ++) { var params = { userId : 1 , productId : 1 , quantity : 1 }; // 通过POST 请求后端,这里的JavaScript 会采用异步请求 $.post (". /purchase ", params , function (result ) { }); }
再次输入 http://localhost:8888/test 进行测试:
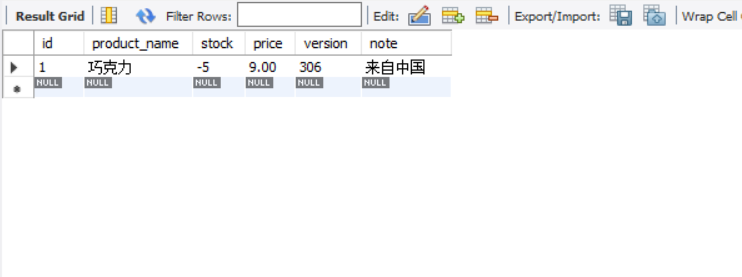
结果:
???? -5?
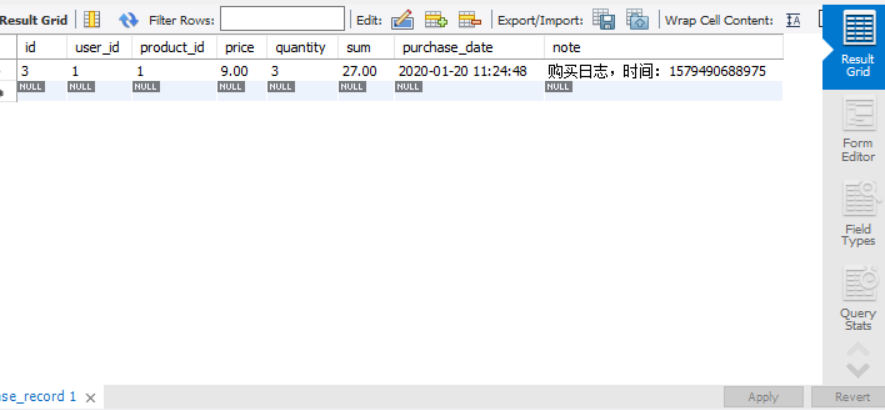
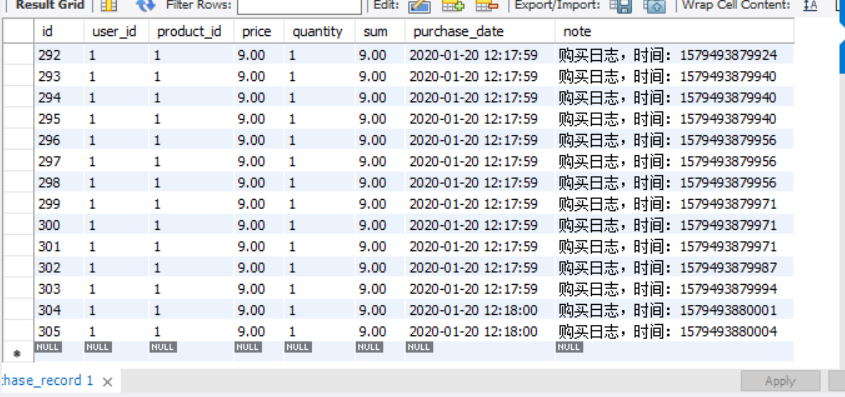
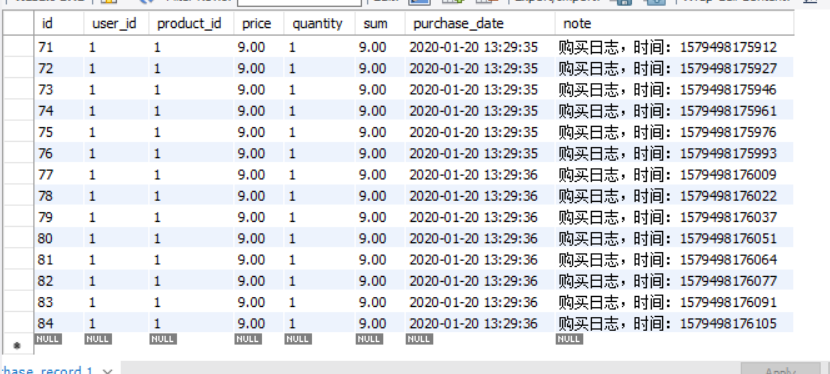
为什么会有这样数据,我们再看看订单表:
确实有着305条订单,显然,数据库事务的读写级别虽然达到了一致性,却没有达到原子性。面对这种情况,根据我们所学的知识,在并发编程里,可以使用锁 去完成。
使用悲观锁 在这样的高并发情况下,最简单粗暴的解决方法就是加锁,下面我们为数据库加一条锁,在xml 加入 for update 。就使用了悲观锁,当前的SQL被执行时,不允许其他线程执行该SQL。
1 2 3 4 5 <select id ="getProduct" parameterType ="long" resultType ="product" > select id, product_name as productName, stock, price, version, note from t_product where id=#{id} for update </select >
再打开 http://localhost:8888/test 进行测试:
我们发现,成功保持了只有300条的订单。但是,在使用这样悲观锁的前提下,数据库的性能会变成很差,效率也就变的缓慢。所以,我们开始引入乐观锁。
使用乐观锁 乐观锁是一种不使用数据库锁和不阻塞线程并发的方案。就是一个线程一开始先读取商品库存数据,保存起来,我们把这些旧数据称之为旧值,然后执行一定的业务逻辑,等到需要对共享数据做修改时,会事先将保存的旧值库存与当前数据库的库存进行比较,如果旧值与当前库存一致,它就认为数据没有被修改过,否则就认为数据已经被修改过,当前计算将不被信任,所以就不再修改任何数据。
这就是多线程的概念 :CAS
然而,这一种方案却会引发一种ABA问题。关于ABA问题,之前在讲AtomicInteger 的时候谈论过,这里再放一个例子:
AbA问题的产生:要了解什么是ABA问题,首先我们来通俗的看一下这个例子,一家火锅店为了生意推出了一个特别活动,凡是在五一期间的老用户凡是卡里余额小于20的,赠送10元,但是这种活动没人只可享受一次。然后火锅店的后台程序员小王开始工作了,很简单就用cas技术,先去用户卡里的余额,然后包装成AtomicInteger,写一个判断,开启10个线程,然后判断小于20的,一律加20,然后就很开心的交差了。可是过了一段时间,发现账面亏损的厉害,老板起先的预支是2000块,因为店里的会员总共也就100多个,就算每人都符合条件,最多也就2000啊,怎么预支了这么多。小王一下就懵逼了,赶紧debug,tail -f一下日志,这不看不知道,一看吓一跳,有个客户被充值了10次!
阐述:
假设有个线程A去判断账户里的钱此时是15,满足条件,直接+20,这时候卡里余额是35.但是此时不巧,正好在连锁店里,这个客人正在消费,又消费了20,此时卡里余额又为15,线程B去执行扫描账户的时候,发现它又小于20,又用过cas给它加了20,这样的话就相当于加了两次,这样循环往复肯定把老板的钱就坑没了!
本质:
ABA问题的根本在于cas在修改变量的时候,无法记录变量的状态,比如修改的次数,否修改过这个变量。这样就很容易在一个线程将A修改成B时,另一个线程又会把B修改成A,造成casd多次执行的问题。
为了解决这样的问题,我们在这个例子中引入了版本号。
增加版本号判断 在xml中修改:
1 2 3 4 5 6 <update id ="decreaseProduct" > update t_product set stock = stock - #{quantity}, version = version +1 where id = #{id} and version = #{version} </update >
在DAO层中修改定义:
1 2 3 public int decreaseProduct (@Param("id" ) Long id, @Param ("quantity" ) int quantity, @Param ("version" ) int version) ;
修改服务层:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Override @Transactional public boolean purchase (Long userId, Long productId, int quantity) ProductPo product = productDao.getProduct(productId); if (product.getStock() < quantity) {return false ;} int version = product.getVersion();int result = productDao.decreaseProduct(productId, quantity, version);if (result == 0 ) {return false ;} PurchaseRecordPo pr = this .initPurchaseRecord(userId, product, quantity); purchaseRecordDao.insertPurchaseRecord(pr); return true ;}
我们看到,我们每次执行都会去数据库读取版本号,如果一致则版本号+1,并且修改,否则则返回false。
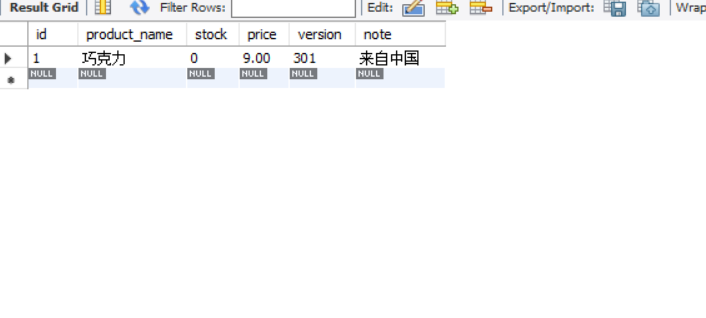
再次测试:
居然还有库存???
显然,大量的请求得到了大量的失败,这就导致了我们500次的读取却只有84次是成功的。
为了解决这个问题,乐观锁还可以引入重入机制,就是一旦更新失败,就重新做一次,而不是结束请求。
按时间戳重入 但是这样又引入了其他问题,比如,SQL被执行的次数总数恐怕达到了上千次。为了克服这个问题,我们引入时间戳的方法来试试重入机制。
修改服务层:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Transactional (isolation = Isolation.READ_COMMITTED)public boolean purchase (Long userId, Long productId, int quantity) long start = System.currentTimeMillis(); while (true ) { long end = System.currentTimeMillis(); if (end - start > 100 ) { return false ; } ProductPo product = productDao.getProduct(productId); int version = product.getVersion(); if (product.getStock() < quantity) { return false ; } int result = productDao.decreaseProduct(productId, quantity, version); if (result == 0 ) { continue ; } PurchaseRecordPo pr = this .initPurchaseRecord(userId, product, quantity); purchaseRecordDao.insertPurchaseRecord(pr); return true ; } }
这里将一个请求限制为100ms的生存期,如果在100ms内发生版本号冲突而不能更新的,则重新尝试,否则请求失败。
开始测试:
可以看到,测试成功了。
但是按照时间戳重入也有一个弊端,那就是系统会随着自身的忙碌而大大减少重入次数,因此有时候也会采用按次数重入的机制。
按次数重入 服务层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Override @Transactional (isolation = Isolation.READ_COMMITTED)public boolean purchase (Long userId, Long productId, int quantity) long start = System.currentTimeMillis(); while (true ) { long end = System.currentTimeMillis(); if (end - start > 100 ) { return false ; } ProductPo product = productDao.getProduct(productId); if (product.getStock() < quantity) { return false ; } int version = product.getVersion(); int result = productDao.decreaseProduct(productId, quantity,version); if (result == 0 ) { continue ; } PurchaseRecordPo pr = this .initPurchaseRecord(userId, product, quantity); purchaseRecordDao.insertPurchaseRecord(pr); return true ; } }
在这里使用for的三重循环进行尝试。三次去尝试获取锁,如果都不能够成功获得,则请求失败。但是使用乐观锁,还是一个相对来说比较复杂的方式,因为在不同场景下势必要在后端中多次更改代码。现在,可以使用Redis缓存,去解决这个问题。
使用Redis处理高并发 在高并发的环境下,仅仅使用数据库去完成业务,是不够的。在前人的摸索中,开发出了一个叫Redis的缓存,去搭配数据库完成业务。
数据库是一个读写磁盘的过程,这个速度显然没有直接写入内存的Redis快。Redis的机制也能够帮助我们克服超发现象。但是,因为其命令方式的运算能力比较薄弱,所以往往采用Redis Luau去代替它原有的命令方式。
Redis Lua在Redis的执行中是具备原子性的,当它被执行时不会被其他客户端发送的命令所打断,通过这样一种机制可以在高并发环境下考虑使用Redis去代替数据库作为响应用户的数据载体。
设计主要分两部分:
先使用Redis响应高并发用户的请求。
启动定时任务将Redis保存到数据库。
配置文件: 1 2 3 4 5 6 7 8 9 10 redis: jedis: pool: min-idle: 5 max-active: 10 max-idle: 10 max-wait: 2000 port: 6379 host: localhost timeout: 1000
服务层 接口:
1 2 3 boolean purchaseRedis (Long userId, Long productId, int quantity) boolean dealRedisPurchase (List<PurchaseRecordPo> prpList)
定制属于Redis的查找和删除
服务:
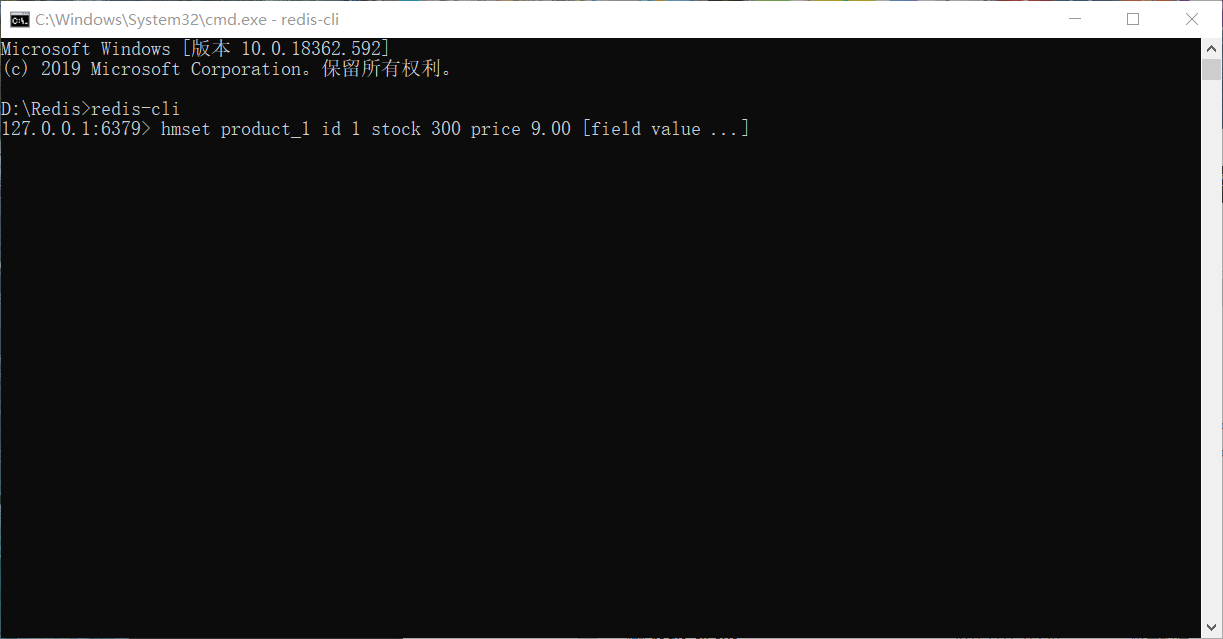
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 @Autowired StringRedisTemplate stringRedisTemplate = null ; String purchaseScript = " redis.call('sadd', KEYS[1], ARGV[2]) \n" + "local productPurchaseList = KEYS[2]..ARGV[2] \n" + "local userId = ARGV[1] \n" + "local product = 'product_'..ARGV[2] \n" + "local quantity = tonumber(ARGV[3]) \n" + "local stock = tonumber(redis.call('hget', product, 'stock')) \n" + "local price = tonumber(redis.call('hget', product, 'price')) \n" + "local purchase_date = ARGV[4] \n" + "if stock < quantity then return 0 end \n" + "stock = stock - quantity \n" + "redis.call('hset', product, 'stock', tostring(stock)) \n" + "local sum = price * quantity \n" + "local purchaseRecord = userId..','..quantity..','" + "..sum..','..price..','..purchase_date \n" + "redis.call('rpush', productPurchaseList, purchaseRecord) \n" + "return 1 \n" ; private static final String PURCHASE_PRODUCT_LIST = "purchase_list_" ; private static final String PRODUCT_SCHEDULE_SET = "product_schedule_set" ; private String sha1 = null ; @Override public boolean purchaseRedis (Long userId, Long productId, int quantity) Long purchaseDate = System.currentTimeMillis(); Jedis jedis = null ; try { jedis = (Jedis) stringRedisTemplate .getConnectionFactory().getConnection().getNativeConnection(); if (sha1 == null ) { sha1 = jedis.scriptLoad(purchaseScript); } Object res = jedis.evalsha(sha1, 2 , PRODUCT_SCHEDULE_SET, PURCHASE_PRODUCT_LIST, userId + "" , productId + "" , quantity + "" , purchaseDate + "" ); Long result = (Long) res; return result == 1 ; } finally { if (jedis != null && jedis.isConnected()) { jedis.close(); } } }
这个代码中的StringRedisTemplate 是由SpringBoot机制自动生成的。
购买记录中使用了Lua语言,会在第一次执行时,把脚本缓存到Redis服务器中,然后Redis会返回一个 32位的SHA1编码,并缓存到变量sha1中,再通过它将程序需要的键和参数传递到后台去执行Lua脚本。Lua脚本会在减少库存后,将信息缓存起来。
注意这一段:
1 2 3 4 Object res = jedis.evalsha(sha1, 2 , PRODUCT_SCHEDULE_SET, PURCHASE_PRODUCT_LIST, userId + "" , productId + "" , quantity + "" , purchaseDate + "" );
局部变量sha1代表一个32位的SHA1编码,用来执行缓存在Redis的脚本中,所以PRODUCT_SCHEDULE_SET和PURCHASE_PRODUCT_LIST都只是键。它们在Lua脚本中以Key[index]表示。而index则是它的索引,以1开始。从第二个参数之后,则都是脚本的参数,在Lua脚本中会以ARGV[index]表示。
最后,保存记录的代码:
1 2 3 4 5 6 7 8 9 10 11 @Override @Transactional (propagation = Propagation.REQUIRES_NEW) public boolean dealRedisPurchase (List<PurchaseRecordPo> prpList) for (PurchaseRecordPo prp : prpList) { purchaseRecordDao.insertPurchaseRecord(prp); productDao.decreaseProduct(prp.getProductId(), prp.getQuantity()); } return true ; }
这个方法将会把购买记录保存到数据库中。
1 @Transactional(propagation = Propagation.REQUIRES_NEW)
这个事务传播行为配置为 Propagation.REQUIRES_NEW 这意味这它会将当前事务挂起,开启新的事务,回滚时只会回滚这个方法的内部事务,而不会影响全局事务。
开启定时任务 启动器上添加:
增加定时任务接口 1 2 3 4 public interface TaskService public void purchaseTask () }
定时任务服务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 @Service public class TaskServiceImpl implements TaskService @Autowired private StringRedisTemplate stringRedisTemplate = null ; @Autowired private PurchaseService purchaseService = null ; private static final String PRODUCT_SCHEDULE_SET = "product_schedule_set" ; private static final String PURCHASE_PRODUCT_LIST = "purchase_list_" ; private static final int ONE_TIME_SIZE = 1000 ; @Override @Scheduled (fixedRate = 1000 * 60 ) public void purchaseTask () System.out.println("定时任务开始......" ); Set<String> productIdList = stringRedisTemplate.opsForSet().members(PRODUCT_SCHEDULE_SET); List<PurchaseRecordPo> prpList =new ArrayList<>(); for (String productIdStr : productIdList) { Long productId = Long.parseLong(productIdStr); String purchaseKey = PURCHASE_PRODUCT_LIST + productId; BoundListOperations<String, String> ops = stringRedisTemplate.boundListOps(purchaseKey); long size = stringRedisTemplate.opsForList().size(purchaseKey); Long times = size % ONE_TIME_SIZE == 0 ? size / ONE_TIME_SIZE : size / ONE_TIME_SIZE + 1 ; for (int i = 0 ; i < times; i++) { List<String> prList = null ; if (i == 0 ) { prList = ops.range(i * ONE_TIME_SIZE, (i + 1 ) * ONE_TIME_SIZE); } else { prList = ops.range(i * ONE_TIME_SIZE + 1 , (i + 1 ) * ONE_TIME_SIZE); } for (String prStr : prList) { PurchaseRecordPo prp = this .createPurchaseRecord(productId, prStr); prpList.add(prp); } try { purchaseService.dealRedisPurchase(prpList); } catch (Exception ex) { ex.printStackTrace(); } prpList.clear(); } stringRedisTemplate.delete(purchaseKey); stringRedisTemplate.opsForSet() .remove(PRODUCT_SCHEDULE_SET, productIdStr); } System.out.println("定时任务结束......" ); } private PurchaseRecordPo createPurchaseRecord ( Long productId, String prStr) String[] arr = prStr.split("," ); Long userId = Long.parseLong(arr[0 ]); int quantity = Integer.parseInt(arr[1 ]); double sum = Double.valueOf(arr[2 ]); double price = Double.valueOf(arr[3 ]); Long time = Long.parseLong(arr[4 ]); Timestamp purchaseTime = new Timestamp(time); PurchaseRecordPo pr = new PurchaseRecordPo(); pr.setProductId(productId); pr.setPurchaseTime(purchaseTime); pr.setPrice(price); pr.setQuantity(quantity); pr.setSum(sum); pr.setUserId(userId); pr.setNote("购买日志,时间:" + purchaseTime.getTime()); return pr; } }
使用@Scheduled定义时间:上一篇文章有写具体该怎么写。
它会从产品列表中读取产品编号,然后根据产品编号找到购买列表。在读出数据后,会转换为POJO对象,通过PurchaseService的createPurchaseRecord方法进行保存。
修改控制层 1 2 3 4 5 6 7 @PostMapping ("/purchase" )public Result purchase (Long userId, Long productId, Integer quantity) boolean success = purchaseService.purchaseRedis(userId, productId, quantity); String message = success ? "抢购成功" : "抢购失败" ; Result result = new Result(success, message); return result; }
最后注意记得删除mapper中的version判定。
测试 在Redis输入:
打开 http://localhost:8888/test 测试:
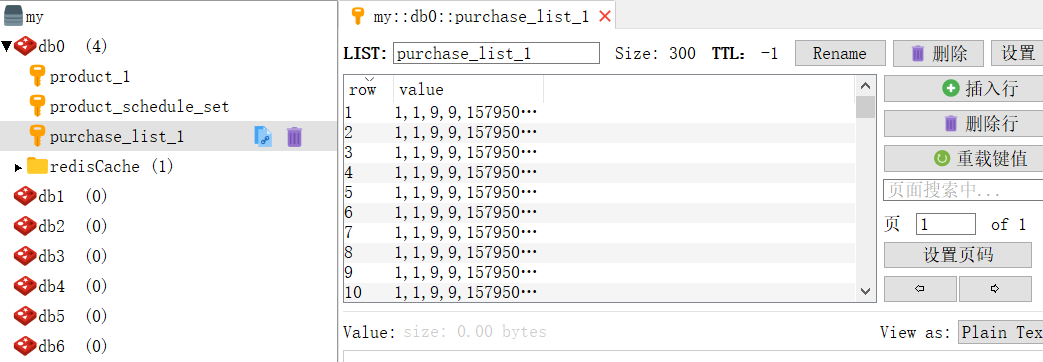
查看Redis:
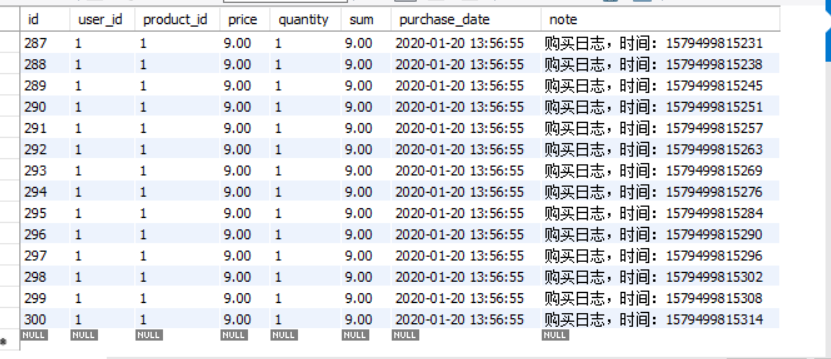
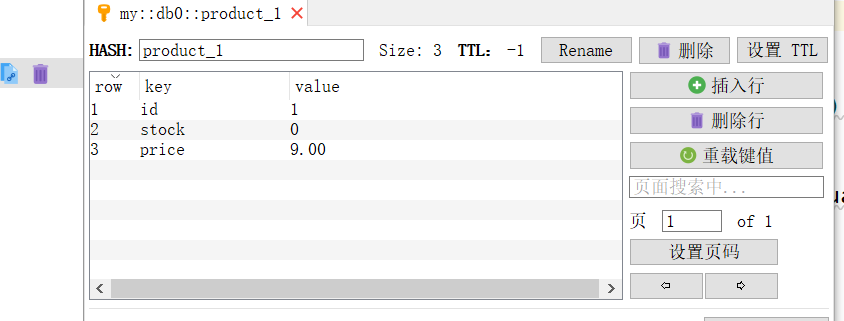
发现多了这些键,这正是我们在业务层定义的键,查看键里包含的值:
发现Redis存储了这次数据库执行的结果,但是还没有写入数据库。在实际应用中,我们可以让Redis在一个夜深人静的夜晚,再缓慢的写回数据库。时间使用@Scheduled定义。
等时间到了,IDEA会出现这段文字:
再去查看数据库,发现成功写回了:
项目地址:https://github.com/Antarctica000/SpringBoot/tree/master/designshop