
ConcurrentHashMap原理
ConcurrentHashMap指的是一个线程安全的HashMap,并且ConcurrentHashMap比起HashTable,拥有这着更高的效率。ConcurrentHashMap更多的时候,是用来代替HahsMap在多线程下进行生产活动。
HashMap线程不安全
要先说为什么HashMap线程不安全,主要有两个原因。
1、put的时候导致的多线程数据不一致。
这个问题比较好想象,比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的桶索引和线程B要插入的记录计算出来的桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
2、另外一个比较明显的线程不安全的问题是HashMap的get操作可能因为resize而引起死循环(cpu100%),具体分析如下:
下面的代码是resize的核心内容:
1 | Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; |
这个方法的功能是将原来的记录重新计算在新桶的位置,然后迁移过去。
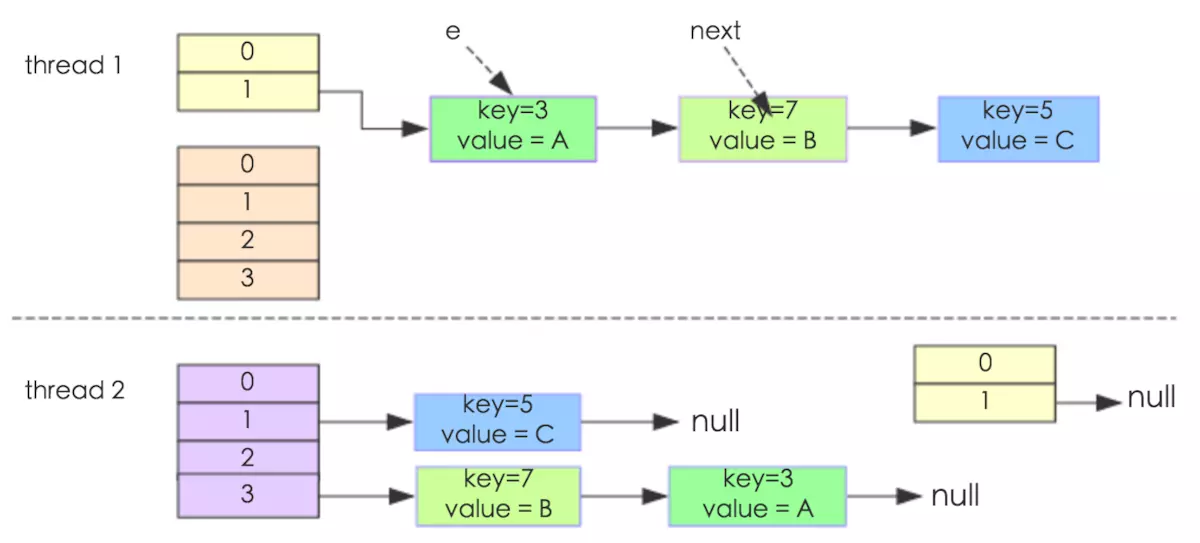
我们假设有两个线程同时需要执行resize操作,我们原来的桶数量为2,记录数为3,需要resize桶到4,原来的记录分别为:[3,A],[7,B],[5,C],在原来的map里面,我们发现这三个entry都落到了第二个桶里面。
假设线程thread1执行到了resize方法的:next = e.next; 这一句,然后时间片用完了,此时的e = [3,A], next = [7,B]。线程thread2被调度执行并且顺利完成了resize操作,需要注意的是,此时的[7,B]的next为[3,A]。
此时线程thread1重新被调度运行,此时的thread1持有的引用是已经被thread2 resize之后的结果。线程thread1首先将[3,A]迁移到新的数组上,然后再处理[7,B],而[7,B]被链接到了[3,A]的后面,处理完[7,B]之后,就需要处理[7,B]的next了啊,而通过thread2的resize之后,[7,B]的next变为了[3,A],此时,[3,A]和[7,B]形成了环形链表,在get的时候,如果get的key的桶索引和[3,A]和[7,B]一样,那么就会陷入死循环。
如果在取链表的时候从头开始取(现在是从尾部开始取)的话,则可以保证节点之间的顺序,那样就不存在这样的问题了。
综合上面两点,可以说明HashMap是线程不安全的。
ConcurrentHashMap做出的改变
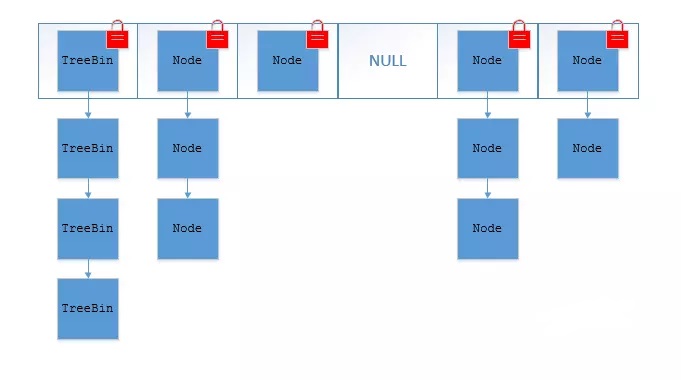
前面也说过,ConcurrentHashMap可以看作为是一个线程安全的HahsMap,在这个前提下,ConcurrentHashMap本身的数据结构和HashMap并没有什么太大的不同,只是在每个数组(或叫做entry、bucket),采用CAS和synchronized来保证并发安全。synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
put()方法
put方法做出了少许改变,毕竟导致hashmap线程不安全的原因之一就是put方法。
1 | public V put(K key, V value) { |
可以根据之前hashmap的解析当中看到,这个put方法在计算hash值的方法是传入到了putval当中进行的,并且在进行添添加节点的时候,进行了CAS操作,来保障hashmap的线程安全。CAS操作之前也讲过,就是在进行交换值的时候,如果已经存在了交换关系,则进行自旋再次尝试。当然,如果 CAS 成功,说明 Node 节点已经插入,随后 addCount(1L, binCount) 方法会检查当前容量是否需要进行扩容。
这里有一个f值,这个putval方法就是根据这个节点的信息去判断接下来该如何行动的。
如果 f 为 null,说明 table 中这个位置第一次插入元素,利用Unsafe.compareAndSwapObject 方法插入 Node 节点。
如果f的 hash 值为 -1,说明当前 f 是 ForwardingNode 节点,意味有其它线程正在扩容,则一起进行扩容操作。
其余情况把新的 Node 节点按链表或红黑树的方式插入到合适的位置,这个过程采用同步内置锁实现并发,代码如下:
1 | synchronized (f) { |
在节点 f 上进行同步,节点插入之前,再次利用tabAt(tab, i) == f判断,防止被其它线程修改。
如果 f.hash >= 0,说明 f 是链表结构的头结点,遍历链表,如果找到对应的 node 节点,则修改 value,否则在链表尾部加入节点。 如果 f 是 TreeBin 类型节点,说明 f 是红黑树根节点,则在树结构上遍历元素,更新或增加节点。 如果链表中节点数 binCount >= TREEIFY_THRESHOLD(默认是8),则把链表转化为红黑树结构。
扩容
ConcurrentHashMap的扩容方法叫做addCount(),当数组不够的时候,便会触发扩容操作。
1 | private final void addCount(long x, int check) { |
在扩容数组的过程中,通过 Unsafe.compareAndSwapInt 修改 sizeCtl 值,保证只有一个线程能够初始化 nextTable,节点从 table 移动到 nextTable,大体思想是遍历、复制的过程。
首先根据运算得到需要遍历的次数i,然后利用 tabAt 方法获得 i 位置的元素 f,初始化一个 forwardNode 实例 fwd。
如果 f == null,则在 table 中的 i 位置放入 fwd,这个过程是采用 Unsafe.compareAndSwapObjectf 方法实现的,很巧妙的实现了节点的并发移动。
如果 f 是链表的头节点,就构造一个反序链表,把他们分别放在 nextTable 的 i 和 i+n 的位置上,移动完成,采用 Unsafe.putObjectVolatile 方法给 table 原位置赋值 fwd。 如果 f 是 TreeBin 节点,也做一个反序处理,并判断是否需要 untreeify,把处理的结果分别放在 nextTable 的 i 和 i+n 的位置上,移动完成,同样采用 Unsafe.putObjectVolatile 方法给 table 原位置赋值 fwd。 遍历过所有的节点以后就完成了复制工作,把 table 指向 nextTable,并更新 sizeCtl 为新数组大小的 0.75 倍 ,扩容完成。
get()方法
get方法是读取map里面的值,并没有做出结果性的修改。
1 | public V get(Object key) { |
size()方法
在JDK8的ConcurrentHashMap中,size方法有了很大的改观。它不再是像HashMap一样是一个类的静态字段了
1 | public int size() { |
我们发现实际上使用的是sumCount方法
1 | final long sumCount() { |
ConcurrentHashMap 提供了 baseCount、counterCells 两个辅助变量和一个 CounterCell 辅助内部类。通过迭代 counterCells 来统计 sum 的过程。而这个counterCells的计算,实际上在putVal方法中,也有说明,是使用CAS去完成的。JDK8的size 是通过对 baseCount 和 counterCell 进行 CAS 计算,最终通过 baseCount 和 遍历 CounterCell 数组得出 size。
JDK7和JDK8的ConcurrentHashMap
或许很多人在看之前的对ConcurrentHashMap介绍中,都提到了segment这个词,但实际上在JDK8版本中,便取消了这个做法。因为在使用segment的时候,虽然也能包保持线程的安全,但随着ConcurrentHashMapd容量的增大,ssegment的并发性并没有什么提高,而改用CAS和synchronized的方式去保持线程安全,在ConcurrentHashMap容量增大的同时,也提高了锁的细化,让ConcurrentHashMap更接近于HahsMap了。
其次是synchronized的升级,让它能够拥有更好的性能,去代替segment的ReentrantLock。
最后是红黑树的引入,这里先不对此做过多解释。