单例模式
单例模式,也就是所谓的工厂模式,单例模式是在设计模式中非常常见的模式,也是应用最为普遍的模式之一。它的特点是:确保系统中的类只产生一个实例。运用这种模式带来的最直观的好处是,减小开销,提高效率。这种模式省略了大量的new操作,对于要大量的使用某些重量级对象的程序而言,有着极大的优化。
1
2
3
4
5
6
7
8
9
| public class Singleton {
private Singleton() {
System.out.println("创建一个实例");
}
private static Singleton instance=new Singleton();
private static Singleton getInstance(){
return instance;
}
}
|
看,这就是一个单例工厂,设置构造函数为私有,让它不能够被随意的使用,设置它的对象为private,保证对象的私有,不会被外界肆意的修改,并且设置获取对象的函数也为私有,保证只会被本类所调用。
之所以这么做,是会让所有需要使用这个类的时候,实例只会在第一次被创建的时候使用new去创建它,之后的每一次使用,都只是return回一个实例而已,这个类没有set方法,也不是public型,可以很好的保证自身的安全。
但是,这样做也会有些不足,比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class singleton {
public static int status=1;
private singleton() {
System.out.println("创建一个实例");
}
private static singleton instance=new singleton();
private static singleton getInstance(){
return instance;
}
}
public class test {
public static void main(String[] args) {
System.out.println(singleton.status);
}
}
创建一个实例
1
|
test只是想要使用一个类里面的静态成员,并没有去创建这个类的实例,但它还是创建了,这个实例,虽然这样并不一定会出错,毕竟singleton也不可被修改,可这终归不可控。但是否可以被改造为可控?当然可以。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class lazysingleton {
public static int status=1;
private lazysingleton() {
System.out.println("创建一个延迟的实例");
}
private static lazysingleton instance=null;
private static synchronized lazysingleton getInstance(){
if(instance==null){
instance=new lazysingleton();
}
return instance;
}
}
public class test {
public static void main(String[] args) {
System.out.println(lazysingleton.status);
}
}
|
可以看到,这样便不会造成问题了,但随之而来的是,加了一个synchronized去保证不会被多次创建的时候,也极大的降低了效率。于是,我们便可以结合两者的优点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class staicsingleton {
public static int status=1;
private staicsingleton() {
System.out.println("创建一个静态的实例");
}
private static class singlrtonholder{
private static staicsingleton instance=new staicsingleton();
}
private static staicsingleton getInstance(){
return singlrtonholder.instance;
}
}
public class test {
public static void main(String[] args) {
System.out.println(staicsingleton.status);
}
}
|
这样结合了两者的特点,使用一个静态的类去调用构造方法,这个和《effective Java》中的用静态方法去代替构造方法,有着异曲同工之妙。
不变模式
不变模式是在设计模式中,最为安全的模式。简而言之,不变模式通过把所有的类和属性,都设置为final型,使得它们永远的不可以被改变,从而保证了自身的安全。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| public final class product {
private final String no;
private final String name;
private final String price;
public String getNo() {
return no;
}
public String getName() {
return name;
}
public String getPrice() {
return price;
}
public product(String no, String name, String price) {
this.no = no;
this.name = name;
this.price = price;
}
}
|
生产者—消费者模式
这个模式可以说是现实生活中很多场景的抽象,之前提到的BlockQueue,就是被运用在这种状态下的。就好似很多程序在被设计之初,如果将接收和处理,这两种操作结合到一起的话,虽然在一定程度上减少了程序的复杂程度,但是这会让整个程序的耦合度变得很高,一旦有什么需求的改动,或者客户端出现了些变化,就会导致整个系统变的更加复杂,甚至生涩难懂。所以,在现在,很多程序的设计都会运用到接收和处理的分离,就好似前端和后端的分离一样,两者变得不再互相依赖,想要这样的条件,就必须引用一个内存缓冲区,来作为数据的传输通道,而它们的实现,正是使用了BlockQueue。
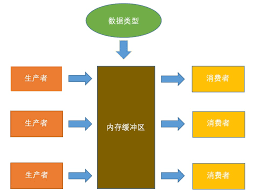
而这个BlockQueue作为内存缓冲区来调节数据的运作。下面用一个实例来展示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
| public class PCData {
private final int intdata;
public PCData(int intdata) {
this.intdata = intdata;
}
public PCData(String intdata) {
this.intdata = Integer.valueOf(intdata);
}
public int getIntdata() {
return intdata;
}
@Override
public String toString() {
return "PCData{" +
"intdata=" + intdata +
'}';
}
}
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class producer implements Runnable{
private volatile boolean isRunning =true;
private BlockingQueue<PCData> queue;
private static AtomicInteger count=new AtomicInteger();
private static final int sleeptime=1000;
public producer(BlockingQueue queue) {
this.queue=queue;
}
@Override
public void run() {
PCData data=null;
Random r=new Random();
System.out.println("生产者线程" +
Thread.currentThread().getId()+"开始运行");
try {
while (isRunning){
Thread.sleep(r.nextInt(sleeptime));
data=new PCData(count.incrementAndGet());
System.out.println("数据入队成功!");
if (!queue.offer(data,2, TimeUnit.SECONDS)){
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
public void stop(){
isRunning=false;
}
}
import com.sun.xml.internal.bind.v2.runtime.output.Pcdata;
import java.text.MessageFormat;
import java.util.Random;
import java.util.concurrent.BlockingQueue;
public class consumer implements Runnable {
private BlockingQueue <PCData> queue;
public static final int sleeptime=1000;
public consumer(BlockingQueue<PCData> queue) {
this.queue = queue;
}
@Override
public void run() {
System.out.println("消费者线程" +
Thread.currentThread().getId()+"开始运行");
Random r=new Random();
try {
while (true){
PCData data=queue.take();
if (null!=data){
int re=data.getIntdata()*data.getIntdata();
System.out.println(MessageFormat.format("{0}*{1}={2}",
data.getIntdata(),
data.getIntdata(),
re));
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.interrupted();
}
}
}
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
public class test {
public static void main(String[] args) throws InterruptedException {
LinkedBlockingQueue queue = new LinkedBlockingQueue(10);
producer producer1=new producer(queue);
producer producer2=new producer(queue);
producer producer3=new producer(queue);
consumer consumer1=new consumer(queue);
consumer consumer2=new consumer(queue);
consumer consumer3=new consumer(queue);
ExecutorService es=Executors.newCachedThreadPool();
es.execute(producer1);
es.execute(producer2);
es.execute(producer3);
es.execute(consumer1);
es.execute(consumer2);
es.execute(consumer3);
Thread.sleep(2000);
producer1.stop();
producer2.stop();
producer3.stop();
Thread.sleep(1000);
es.shutdown();
}
}
消费者线程15开始运行
生产者线程14开始运行
消费者线程16开始运行
生产者线程13开始运行
生产者线程12开始运行
消费者线程17开始运行
数据入队成功!
1*1=1
数据入队成功!
2*2=4
数据入队成功!
3*3=9
数据入队成功!
4*4=16
数据入队成功!
5*5=25
数据入队成功!
6*6=36
数据入队成功!
7*7=49
数据入队成功!
8*8=64
数据入队成功!
9*9=81
数据入队成功!
10*10=100
|
可见 LinkedBlockingQueue这个队列承担了内存的缓冲区,作为一个程序的中间件,使得生产者和消费者连接起来,即使生产者并不认识消费者,也不知道彼此的工作方式,也可以通过建立缓冲区的方式,将它们连接起来。
Disruptor:高性能的生产者和消费者框架
既然大家都能想的到用队列去实现内存缓冲区,那么也会有人想到该怎么去优化它,使其变的更好用,于是,一家名为LMAX的公司,便开发了一个高效的无锁内存队列,那就是Disruptor。Disruptor框架中,使用了一个环形的队列,叫做ringbuffer,这是一个有头尾两个指针的队列,而且数组大小为2的次幂。因为ringbuffer使用的是位运算符,它的sequence(队列)通过和queueSize-1的值做&(与运算),能够快速的定位到实际元素的位置。注意,它和普通的环形队列相比,它并没有使用出队这个操作,而是用新覆盖旧元素的方法,去减少空间的分配和回收所需要的开销。
重新实现这个案例
我们可以尝试着用ringbuffer去重新实现它:(注:这需要外接一个jar包,jdk并不自带)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
| public class PCData {
private long value;
public PCData() {
}
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
public PCData(long value) {
this.value = value;
}
}
import com.lmax.disruptor.EventFactory;
public class PCDFactory implements EventFactory<PCData> {
@Override
public PCData newInstance() {
return new PCData();
}
}
import com.lmax.disruptor.RingBuffer;
import java.nio.ByteBuffer;
public class producer {
private final RingBuffer<PCData> ringBuffer;
public producer(RingBuffer<PCData> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void pushData(ByteBuffer bb){
long sequence = ringBuffer.next();
try {
PCData event =ringBuffer.get(sequence);
event.setValue(bb.getLong(0));
}finally {
ringBuffer.publish(sequence);
}
}
}
import com.lmax.disruptor.WorkHandler;
public class consumer implements WorkHandler<PCData> {
@Override
public void onEvent(PCData o) throws Exception {
System.out.println(Thread.currentThread().getId()+"线程正在消费" +
o.getValue()*o.getValue());
}
}
import com.lmax.disruptor.BlockingWaitStrategy;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import java.nio.ByteBuffer;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class test {
public static void main(String[] args) throws InterruptedException {
ExecutorService es= Executors.newCachedThreadPool();
PCDFactory f=new PCDFactory();
int size=1024;
Disruptor<PCData> disruptor=new Disruptor<PCData>(f,
size,
es,
ProducerType.MULTI,
new BlockingWaitStrategy());
disruptor.handleEventsWithWorkerPool(
new consumer(),
new consumer(),
new consumer(),
new consumer()
);
disruptor.start();
RingBuffer<PCData> ringBuffer=disruptor.getRingBuffer();
producer p=new producer(ringBuffer);
ByteBuffer bb= ByteBuffer.allocate(8);
for (long i = 0; true ; i++) {
bb.putLong(0,i);
p.pushData(bb);
Thread.sleep(1000);
System.out.println("增加数据:"+i);
}
}
}
13线程正在消费0
增加数据:0
16线程正在消费1
增加数据:1
15线程正在消费4
增加数据:2
14线程正在消费9
增加数据:3
13线程正在消费16
增加数据:4
16线程正在消费25
增加数据:5
15线程正在消费36
增加数据:6
14线程正在消费49
增加数据:7
13线程正在消费64
增加数据:8
16线程正在消费81
增加数据:9
15线程正在消费100
增加数据:10
14线程正在消费121
增加数据:11
13线程正在消费144
增加数据:12
16线程正在消费169
增加数据:13
15线程正在消费196
增加数据:14
14线程正在消费225
|
消费者在继承了WorkHandler的接口后,会要求重写消费该队列的方法,每次在生产者中使用了ringBuffer.publish(sequence);加入一个元素后,消费者会自动去调用重写的消费方法,去使用这个元素,比如求这个元素的平方。之所以使用bytebuffer去存储元素,是因为它能够存放任何的数据类型。每次存放一个数据后,都要使用next方法去继续获得下一个元素所存放的盒子。整个数据结构的图示如下:
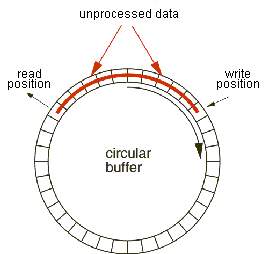
选择合适的策略
Disruptor在制作的时候,最后一个参数叫做BlockingWaitStrategy,这是disruptor的一个默认的策略,它和blockqueue非常类似,都是使用阻塞的方式,使用锁和条件(condition)进行阻塞,这种情况下非常节省cpu的使用,但使用着阻塞,便意味着在高并发的情况下,效果不会那么理想。接下来总结一个有哪些策略:
- sleepWaitStrategy:这个策略虽然不进行将线程挂起的操作,但是会使用自旋的方式让获取资源,这个策略不会占用太多的CPU资源,但是对数据处理效率也不高,甚至比阻塞的效率更低一点。好处就是,对生产者线程的影响非常小,比较适合异步日志。
- BlockingWaitStrategy:使用锁和条件去阻塞队列,保证线程安全,但在高并发情况下效率低下。
- YieldWaitStrategy:这个策略去CPU要求很高,消费者非常疯狂的去获得生产者所加入的元素,因为它的消费者会在内部执行一个Threa.yield的死循环。
- BusySpinWaitStrategy:这个策略效率非常非常的高,但是它会使用掉几乎所有的CPU资源。
CPU的Cache优化
上述的一些策略,都是为了调节CPU资源等等的问题,可见CPU在程序中的重要性,我们除了要从框架上优化和调节CPU的使用之外,我们也要稍微了解一下CPU的机制,在讲述volatile的时候,使用了这一张图: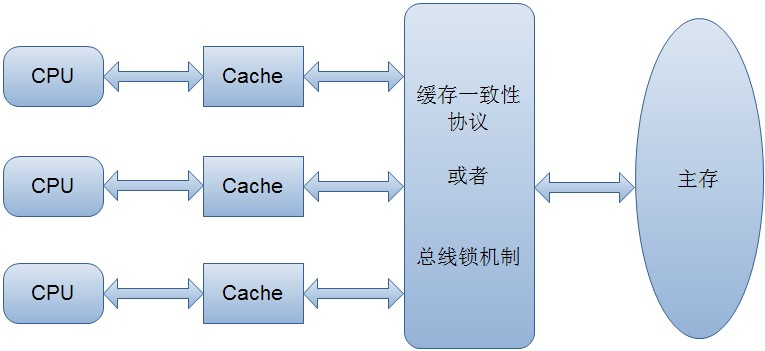
这张图也可以表示出,CPU都是从缓存中获取数据。但是要注意,每个数据被加入到cache中的时候,并不是单个单个存在的:
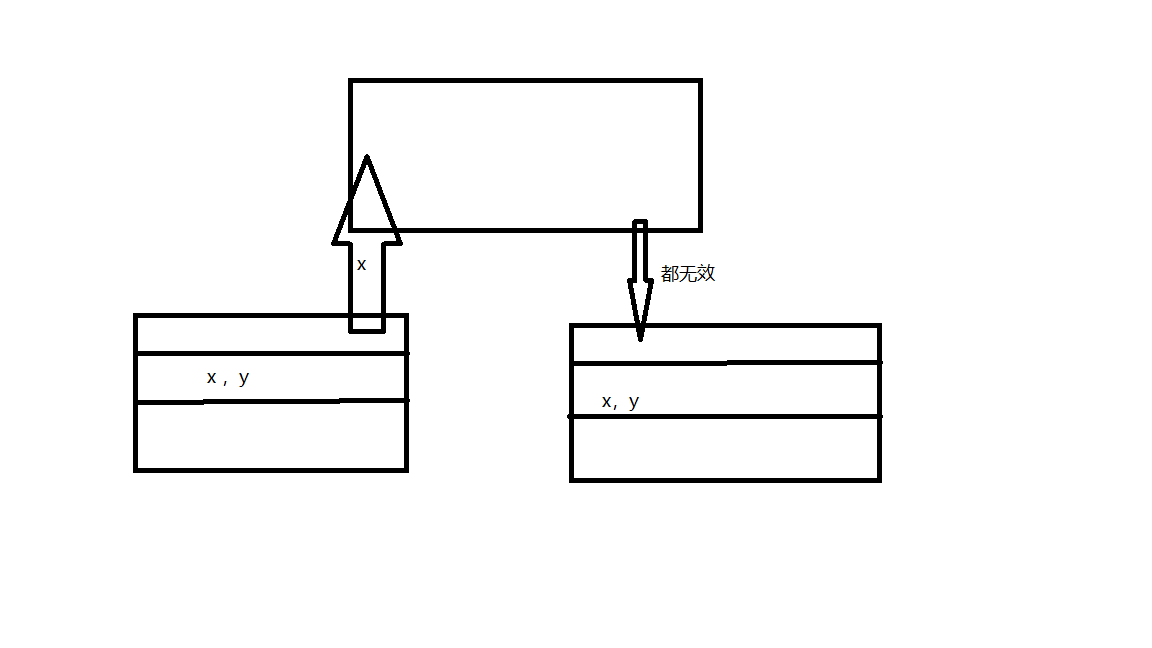
像这样,每次在将一个新的x被更新后,就会使得所有和x层所在的元素,一同被声明为无效,对于这样的情况,我们的程序都可以想办法对cpu进行优化,这优化在《Java并发编程艺术》一书中也有所提及,就是想办法将其凑够一行,如图:
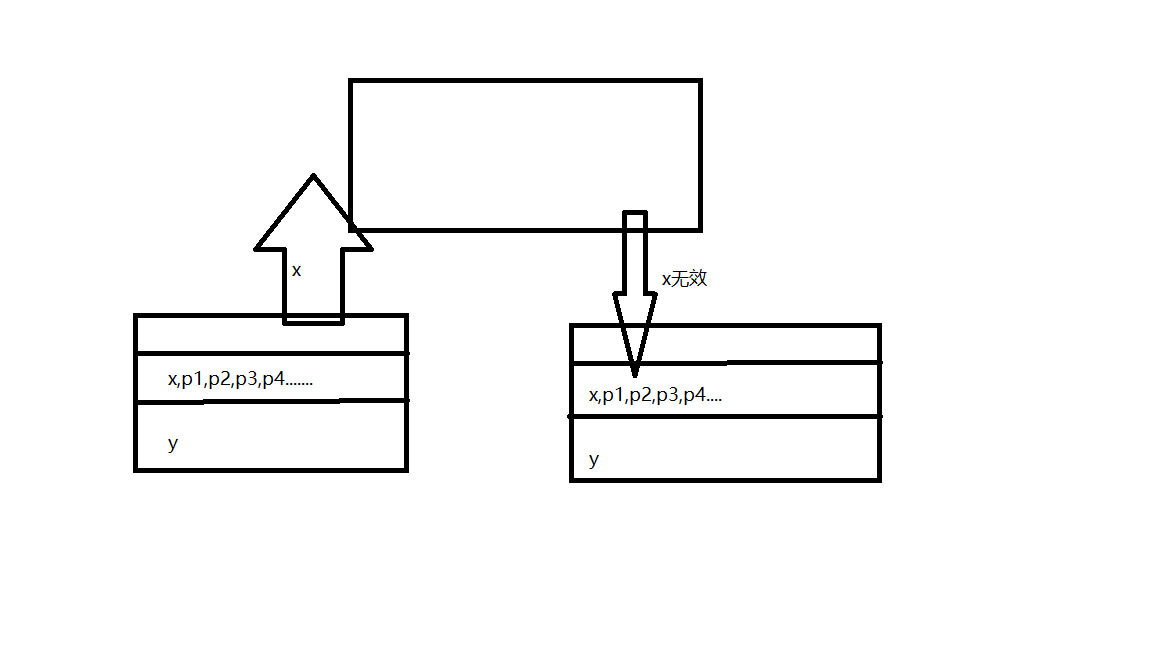
这样,每次被声明无效过后,只有x会被无效化,而y不会,这也是典型的以空间去换时间的做法,那我们可以在实际中试一试看看真的能不能提高效率。(注:使用JDK7)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| public final class 解决cpu的cache优化问题 implements Runnable {
public static final int NUM_THREADS=2;
public static final long ITERATIONS=500L*1000L*1000L;
private final int arrayindex;
public 解决cpu的cache优化问题(int arrayindex) {
this.arrayindex = arrayindex;
}
public final static class VolatileLong{
public long q1,q2,q3,q4,q5,q6,q7;
public volatile long value=0L;
public long p1,p2,p3,p4,p5,p6,p7;
}
private static VolatileLong[] longs=new VolatileLong[NUM_THREADS];
static {
for (int i = 0; i <longs.length ; i++) {
longs[i]=new VolatileLong();
}
}
public static void main(String[] args) throws InterruptedException {
final long start =System.currentTimeMillis();
Runtest();
System.out.println("持续时间="+(System.currentTimeMillis()-start));
}
private static void Runtest() throws InterruptedException {
Thread[] ts=new Thread[NUM_THREADS];
for (int i = 0; i <ts.length ; i++) {
ts[i]=new Thread(new 解决cpu的cache优化问题(i));
}
for (Thread t:
ts) {
t.start();
}
for (Thread t:
ts) {
t.join();
}
}
@Override
public void run() {
long i=ITERATIONS+1;
while (0!=--i){
longs[arrayindex].value=i;
}
}
}
|
那我们把填充物给注释掉呢,看看结果会怎么样。
可以看到性能差距非常之大。为什么呢?因为CPU的每次缓存,都是缓存64的字节数,一个对象的引用一般占用4个字节,而在这里填充15个字节,使得缓存满64个字节,这样,便优化了效率。
但是注意,这里使用的是JDK7,因为jdk8会自动优化不使用的字段,这样我们的填充物就被所谓的 “优化”给优化没了,这可能就是所谓的负优化把……
而我们所使用的Disruptor就考虑到了这一层,所以,在总体实现上Disruptor的ringbuffer队列会比传统的LinkingBlockQueue快了很多。
