
隐蔽的错误
在编程当中遇到错误,可能会让你头疼,但能提示出是哪里出现了某某错误,也许只是一两分钟就能解决的问题,最可怕的是,程序出错了,却没有任何提示,得自己慢慢的去找,在几十万行代码的工程当中,可能分分钟就猝死了。所以,写任何代码时,都要想一想各种会出现的问题,最简单的不可见错误如下:
1 | int v1=1073741827; |
程序不会提示出你的代码错误,甚至可以说,从逻辑上而言完全没有错误,但隐藏的错误就是,值溢出了,这会使最后的结果出现了错误。
并且,在并行开发中,这样的隐藏错误还会有更多更多。
ArrayList
ArrayList在java中是一个经常被使用的容器。它的就相当于一个可以存放任何类型的、自动扩容的数组。我们看看下面这段代码,看它为什么线程不安全。
1 | import java.util.ArrayList; |
第一种情况,就是如上所述,数组越界的错误,我们看看为什么会数组越界,首先这个越界发生在add这个方法中
1 | public boolean add(E e) { |
- 此时,t1线程和t2线程同时对ArrayList进行扩容:
t1发现list为10,不够存放,需要扩容到11,调用ensureCapacityInterna进行判断 - t2发现list为10,不够存放,需要扩容到11,也调用ensureCapacityInterna进行判断
- t1发现扩容后大小为11,可以容纳,不再扩容,返回
- t2也发现扩容后大小为11,可以容纳,直接返回(这里的t2的判断容量的过程恰好在t1刚扩容完后)
- t1开始进行设置值操作, elementData[size++] = e 操作。此时size变为11
- t2也开始进行设置值操作,它尝试设置elementData[11] = e,而elementData没有进行过扩容,它的下标最大为10。于是此时会报出一个数组越界的异常ArrayIndexOutOfBoundsException
于是乎,错误就这么诞生了,所以ArrayList线程不安全,可以使用vector代替,而vector之所以线程安全,那是因为它在扩容过程中使用了synchronize进行加锁,ArrayList代表效率,vector代表安全,看各种情况去使用它们。
第二种情况,它运气极好,没有发生冲突,恰好为200000。
第三种情况,183274,这种情况是一种非常隐蔽的错误,它既没有显式的表达出错误,也没有计算正确,这是因为两个线程同时对i进行赋值,导致的错误,这种错误不是属于逻辑上的错误,所以不会直接的表达,而是直接的被略过。
HashMap
HashMap的原理
HashMap是一个非常之重要的容器,几乎每一个互联网公司的面试都会问及HashMap的实现和原理,hashmap首先是一个可扩容的数组,然后每个数组底下可以存放多个内容,被存放的内容就像链表一样,一个接着一个,在一个数组存放的链表大于8个的时候,链表就会转化为红黑树的数据结构,这里先简要概述HashMap的原理
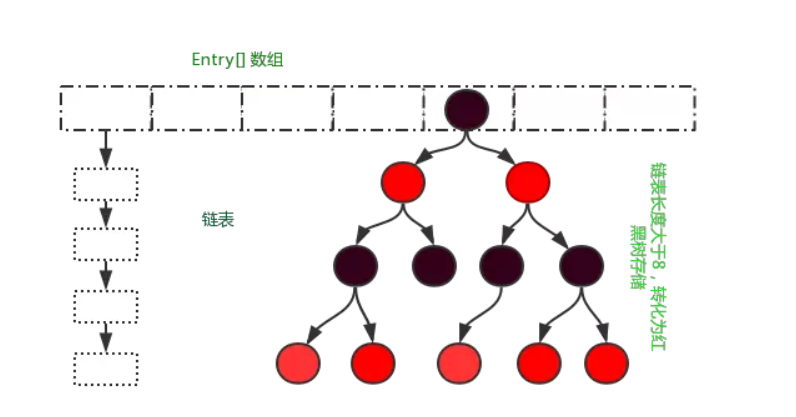
hashmap的设计可以说非常的及精妙,它结合了数组和链表的特点,数组是寻址容易,修改和插入困难,而链表反之,hashmap不仅仅寻址容易,插入和删除也容易。所以,hashmap可以看成是一个带有链表的数组,它的使用方法和图一样,一个key值,一个value值。
我们先看看hashmap的构造函数
1 | public HashMap() { |
这里写出了,hashmap的构造和扩容的机制,在构造的时候设置了负载因子0.75,以用来在hashmap的元素在达到其四分之三的时候,便会自发的发生扩容,为什么必须是0.75的时候呢,在这里,设计者给出了一个解释 nodes in bins follows a Poisson distribution。什么是poisson分布呢,用通俗的语言来说,世界上的概率都是可以通过计算得来的,比如硬币的概率是二分之一,但是若要涉及的各种各样的因素,比如风力,重力,地球的自转,或许就会与实际相差那么一点点,于是可以把概率分成有大数据支持的概率(正态分布),没大数据支持的概率(二项式分布),现实生活中的概率(poisson分布)。使用poisson分布在hashmap中,是为了减少hash冲突(又称碰撞)。
什么是哈希冲突?哈希冲突是指哈希码被放入到hashmap的时候发生的重叠,也可以看作为:两个不同的输入值,根据同一散列函数计算出的散列值相同的现象叫做碰撞。如下:
1 | t.put(17,"you"); |
再回来看看put函数返回的putval函数
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
总结为是通过hash(key)%len的方式,将hashcode其存放在hashmap当中,于是put里的key值17就变成了hashcode:1
而且,hashmap虽然在构造的时候,可以传入任意参数但其实,无论传入什么参数,最后都会变成2的次幂。
长度16或者其他2的幂,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于hashcode后几位的值。只要输入的hashcode本身分布均匀,Hash算法的结果就是均匀的。所以,hashmap中的&位必须为奇数(Length - 1)
因为2的次幂可以很好的去减少hash碰撞,并且呢,虽然我们说hashcode其实是对容量取余获得的,但是由于取余这个方法在计算中并不是那么有效率,所以实际上还是通过位运算的方式去取得余,不过我们可以概念性的看作为取余,方便运算,并且位运算还有一个好处就是,可以解决负数的问题。
为什么可以使用位运算(&)来实现取模运算(%)呢?这实现的原理如下:
- X % 2^n = X & (2^n – 1)
- 2^n表示2的n次方,也就是说,一个数对2^n取模 == 一个数和(2^n – 1)做按位与运算 。
- 假设n为3,则2^3 = 8,表示成2进制就是1000。2^3 -1 = 7 ,即0111。
- 此时X & (2^3 – 1) 就相当于取X的2进制的最后三位数。
- 从2进制角度来看,X / 8相当于 X >> 3,即把X右移3位,此时得到了X / 8的商,而被移掉的部分(后三位),则是X % 8,也就是余数。
而通常解决hash碰撞有这几种方法:
- 开放定址法:
- 开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
- 链地址法
- 将哈希表的每个单元作为链表的头结点,所有哈希地址为i的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
- 再哈希法
- 当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。
- 建立公共溢出区
- 将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
为什么HashMap线程不安全
我们先来看一段代码
1 | import java.util.HashMap; |
这段代码和ArrayList非常类似,也会出现三种情况
第一种情况就是运行结果为100000,也就是运气极佳,完美运行,但这种情况很少
第二种情况就是有结果,但结果少于100000,这是因为访问时出现了数据的不一致
但更多的是第三种情况,出现了程序一直在运行,无限循环的情况,为什么会出现这种情况呢,想必大家第一时间能想的到是因为put方法,对,没错,不同ArrayList的数组越界错误,hashmap出现了死循环
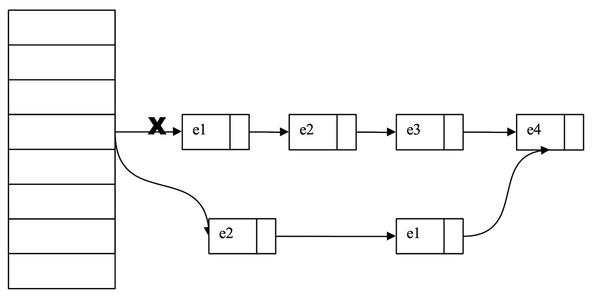
hashmap扩容的时候,会出现链表互为对方的next的情况,从而导致一个死循环
不过jdk1.8之后,已经不存在这个问题了(jdk1.7及以下仍然存在),即使这样,hashmap在多线程中也要谨慎使用,最好的方法是使用concurrenthashmap去代替hashmap
错误的加锁
这里要提到一个新的观点,被synchronize包围的对象,就一定能保持原子性吗?
1 | public class test implements Runnable { |
如上代码所示,这是一个比较简单的事例,一个计数器,最后算出结果,我们从表面上看,这个列子完全没有问题,所用的对象i也完全被包围,那么我们看一下结果
1 | 153039 |
这并不等于200000。很可能是在读写的过程中发生了数据不一致的错误。这是为什么呢?我们来看看Integer的实现。
我们发现了Integer的增长过程
1 | public static Integer valueOf(int i) { |
我们可以看到,valueof实际上是一个工厂方法,它会返回一个指定数值的Integer实例,因此这里的i++本质上是
1 | i=Integer.valueOf(i.intValue()+1); |
因为在多个线程之间,i在不断地变动,所以我们锁住的Integer都是过去的Integer,想要修正这个问题,也很简单,只要把synchronize那一部分变成
1 | synchronized (instance){ |
这样锁住的部分就变成了该线程本身。